Rebase and skip HashStoreTest for win32#2
Merged
siva1007 merged 134 commits intocomp_set_issue_#53062from Mar 11, 2021
Merged
Conversation
Summary: Pull Request resolved: pytorch#53478 This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM). New submodule commit: pytorch/FBGEMM@c3612e6 Pull Request resolved: pytorch#53087 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: jianyuh Differential Revision: D26744074 Pulled By: jspark1105 fbshipit-source-id: c16de118a5befb9dae9e256a5796993cdcfb714b
…ction (pytorch#53202) Summary: Pull Request resolved: pytorch#53202 Test Plan: Imported from OSS Reviewed By: H-Huang Differential Revision: D26791525 Pulled By: mrshenli fbshipit-source-id: 8234c4d0350a5cd61926dce4ecc9e918960d30d2
Summary: Pull Request resolved: pytorch#53209 closes pytorch#40048 Test Plan: Imported from OSS Reviewed By: H-Huang Differential Revision: D26791524 Pulled By: mrshenli fbshipit-source-id: fc75589f9707014334fcfae6f05af3c04217783b
Summary: This PR adds an implementation for `aten::cat` in NNC without any conditionals. This version is not enabled by default. Here is the performance of some micro benchmarks with and without conditionals. There is up to 50% improvement in performance without conditionals for some of the shapes. aten::cat implementation in NNC **with** conditionals ``` $ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion concat pt: concat2d2input_fwd_cpu_1_160_1_14_1: 5.44 us, SOL 0.26 GB/s, algorithmic 0.51 GB/s pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.75 us, SOL 1.05 GB/s, algorithmic 2.10 GB/s pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.87 us, SOL 4.05 GB/s, algorithmic 8.11 GB/s pt: concat2d2input_fwd_cpu_20_580_20_174_1: 14.52 us, SOL 8.31 GB/s, algorithmic 16.62 GB/s pt: concat2d2input_fwd_cpu_8_512_8_512_1: 9.58 us, SOL 6.84 GB/s, algorithmic 13.68 GB/s ``` aten::cat implementation in NNC **without** conditionals ``` $ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion --cat_wo_conditionals concat pt: concat2d2input_fwd_cpu_1_160_1_14_1: 4.67 us, SOL 0.30 GB/s, algorithmic 0.60 GB/s pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.65 us, SOL 1.07 GB/s, algorithmic 2.14 GB/s pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.10 us, SOL 4.56 GB/s, algorithmic 9.12 GB/s pt: concat2d2input_fwd_cpu_20_580_20_174_1: 7.44 us, SOL 16.22 GB/s, algorithmic 32.44 GB/s pt: concat2d2input_fwd_cpu_8_512_8_512_1: 6.46 us, SOL 10.14 GB/s, algorithmic 20.29 GB/s ``` Pull Request resolved: pytorch#53128 Reviewed By: bertmaher Differential Revision: D26758613 Pulled By: navahgar fbshipit-source-id: 00f56b7da630b42bc6e7ddd4444bae0cf3a5780a
…ytorch#52387) Summary: Related to pytorch#50006 Follow on for pytorch#48560 to ensure TORCH_WARN_ONCE warnings are caught. Most of this is straight-forward find-and-replace, but I did find one place where the TORCH_WARN_ONCE warning was not wrapped into a python warning. Pull Request resolved: pytorch#52387 Reviewed By: albanD Differential Revision: D26773387 Pulled By: mruberry fbshipit-source-id: 5be7efbc8ab4a32ec8437c9c45f3b6c3c328f5dd
…ests consistent (pytorch#53181) Summary: Reference: pytorch#42515 This PR also enables the OpInfo tests on ROCM to check the same dtypes that of CUDA. Note: Reland pytorch#51944 Pull Request resolved: pytorch#53181 Reviewed By: zhangguanheng66 Differential Revision: D26811466 Pulled By: mruberry fbshipit-source-id: 8434a7515d83ed859db1b2f916fad81a9deaeb9b
…ke CLANGFORMAT` Reviewed By: zertosh Differential Revision: D26879724 fbshipit-source-id: 0e2dd4c5f7ba96e97e7cbc078184aed2a034ad2c
Summary: Pull Request resolved: pytorch#53498 This code depended on `Blobs()` being returned in sorted order: https://www.internalfb.com/intern/diffusion/FBS/browsefile/master/fbcode/caffe2/caffe2/python/db_file_reader.py?commit=472774e7f507e124392491800d9654e01269cbaf&lines=89-91 But D26504408 (pytorch@69bb0e0) changed the underlying storage to a hashmap, so now the blobs are returned in arbitrary order (Note that `Blobs()` returns also non-local blobs, and for those there was already no guarantee of ordering). So we need to explicitly sort the result. Test Plan: ``` $ buck test dper3/dper3/toolkit/tests:lime_test $ buck test //dper3/dper3/toolkit/tests:model_insight_test ``` Pass after this diff. Differential Revision: D26879502 fbshipit-source-id: d76113f8780544af1d97ec0a818fb21cc767f2bf
…ytorch#53250) Summary: This is a more fundamental example, as we may support some amount of shape specialization in the future. Pull Request resolved: pytorch#53250 Reviewed By: navahgar Differential Revision: D26841272 Pulled By: Chillee fbshipit-source-id: 027c719afafc03828a657e40859cbfbf135e05c9
…3457) Summary: Currently it says it does a deepcopy by default, but that's not true. Pull Request resolved: pytorch#53457 Reviewed By: navahgar Differential Revision: D26876781 Pulled By: Chillee fbshipit-source-id: 26bcf76a0c7052d3577f217e79545480c9118a4e
Summary: To fix some rendering issues. Pull Request resolved: pytorch#53363 Reviewed By: izdeby Differential Revision: D26884560 Pulled By: albanD fbshipit-source-id: fedc9c9972a6c68f311c6aafcbb33a3a881bbcd2
Summary: Pull Request resolved: pytorch#53508 closes pytorch#53501 Differential Revision: D26885263 Test Plan: Imported from OSS Reviewed By: H-Huang Pulled By: mrshenli fbshipit-source-id: dd0493e6f179d93b518af8f082399cacb1c7cba6
Summary: This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe). New submodule commit: pytorch/tensorpipe@46949a8 Pull Request resolved: pytorch#53504 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: lw Differential Revision: D26883701 fbshipit-source-id: 9e132a1389ac9cee9507c5600668af1afbb26efd
Summary: See pytorch#53526. We're disabling the test temporarily until we can figure out what's going on (since it's unclear what needs to be reverted). Pull Request resolved: pytorch#53527 Reviewed By: zhangguanheng66 Differential Revision: D26888037 Pulled By: samestep fbshipit-source-id: f21a2d665c13181ed3c8815e352770b2f26cdb84
…ytorch#53428) Summary: Pull Request resolved: pytorch#53428 Start to do some code clean up work. ghstack-source-id: 123038070 Test Plan: - CircleCI - Sandcastle CI - AIBench Reviewed By: SS-JIA, AshkanAliabadi Differential Revision: D26681115 fbshipit-source-id: b1b7cfc6543b73928f517cd52e94a2664ee0bd21
Summary: Pull Request resolved: pytorch#53514 Test Plan: ``` tools/test_history.py columns --ref=0ca029b22d17d236d34bcecad44b94b35b1af4bb test_common_errors pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_test1 ``` Reviewed By: janeyx99 Differential Revision: D26886385 Pulled By: samestep fbshipit-source-id: d3d79282e535707616d992ab8cf6216dfb777639
Summary: Pull Request resolved: pytorch#53412 Docker builds for scheduled workflows still need to happen within the regular build workflow since new docker image builds are actually only done within the `build` workflow A follow up to pytorch#52693 Signed-off-by: Eli Uriegas <eliuriegas@fb.com> Test Plan: Imported from OSS Reviewed By: janeyx99 Differential Revision: D26890300 Pulled By: seemethere fbshipit-source-id: d649bfca5186a89bb5213865f1f5738b809d4d38
Summary: Pull Request resolved: pytorch#53489 It appears that D26675801 (pytorch@1fe6a65) broke Glow builds (and probably other instals) with the inclusion of the python_arg_parser include. That dep lives in a directory of its own and was not included in the setup.py. Test Plan: OSS tests should catch this. Reviewed By: ngimel Differential Revision: D26878180 fbshipit-source-id: 70981340226a9681bb9d5420db56abba75e7f0a5
Summary: Pull Request resolved: pytorch#53153 This diff is a fix for quantization_test in operator_benchmark, which is broken because of removing the py_module for learnable fake_quantization. ghstack-source-id: 123103477 Test Plan: `buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:quantization_test` Reviewed By: z-a-f Differential Revision: D26764881 fbshipit-source-id: 8d40c6eb5e7090ca65f48982c837f7dc87d14378
…torch#52769) Summary: Enable partial explicit Aten level sources list for lite interpreter. More aten level source list will be added. x86: `SELECTED_OP_LIST=/Users/chenlai/Documents/pytorch/experiemnt/deeplabv3_scripted.yaml BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` libpytorch_jni_lite.so -- 3.8 MB armeabi-v7a `SELECTED_OP_LIST=/Users/chenlai/Documents/pytorch/experiemnt/deeplabv3_scripted.yaml BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh armeabi-v7a` libpytorch_jni_lite.so -- 2.8 MB Pull Request resolved: pytorch#52769 Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D26717268 Pulled By: cccclai fbshipit-source-id: 208300f198071bd6751f76ff4bc24c7c9312d337
…h#53388) Summary: Pull Request resolved: pytorch#53388 Most of this method did not depend on the template parameter. No need to include it in the .h file or duplicate it in the generated code. ghstack-source-id: 123211590 Test Plan: Existing CI should cover this Reviewed By: smessmer Differential Revision: D26851985 fbshipit-source-id: 115e00fa3fde547c4c0009f2679d4b1e9bdda5df
…rch#53389) Summary: Pull Request resolved: pytorch#53389 Resize was written to take arguments by value, which was totally fine if they were ArrayRef or a series of integers, but not so fine if they're std::vector. ghstack-source-id: 123212128 Test Plan: Existing CI should make sure it builds Inspected assembly for ios_caffe.cc and saw no more vector copy before calling Resize Reviewed By: smessmer Differential Revision: D26852105 fbshipit-source-id: 9c3b9549d50d32923b532bbc60d0246e2c2b5fc7
Summary: We implement a hierarchical fine grained binning structure, with the top level corresponding to different feature segments and bottom level corresponding to different range of ECTR. The model is designed to be general enough to perform segmented calibration on any useful feature Test Plan: buck test dper3/dper3/modules/calibration/tests:calibration_test -- test_histogram_binning_calibration_by_feature buck test dper3/dper3_models/ads_ranking/model_impl/mtml/tests:mtml_lib_test -- test_multi_label_dependent_task_with_histogram_binning_calibration_by_feature e2e test: buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_histogram_binning_calibration_by_feature buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_mtml_with_dependent_task_histogram_binning_calibration_by_feature All tests passed Canary packages: Backend -> aml.dper2.canary:e0cd05ac9b9e4797a94e930426d76d18 Frontend -> ads_dper3.canary:55819413dd0f4aa1a47362e7869f6b1f Test FBL jobs: **SparseNN** ctr mbl feed f255676727 inline cvr f255677216 **MTML regular task** offsite cvr f255676719 **MTML dependent task** mobile cvr f255677551 **DSNN for AI models** ai oc f255730905 **MIMO for both AI DSNN part and AF SNN part** mimo ig f255683062 Reviewed By: zhongyx12 Differential Revision: D25043060 fbshipit-source-id: 8237cad41db66a09412beb301bc45231e1444d6b
…in CI (macos) (pytorch#52566) Summary: ## Summary 1. Enable building libtorch (lite) in CI (macos) 2. Run `test_lite_interpreter_runtime` unittest in CI (macos) 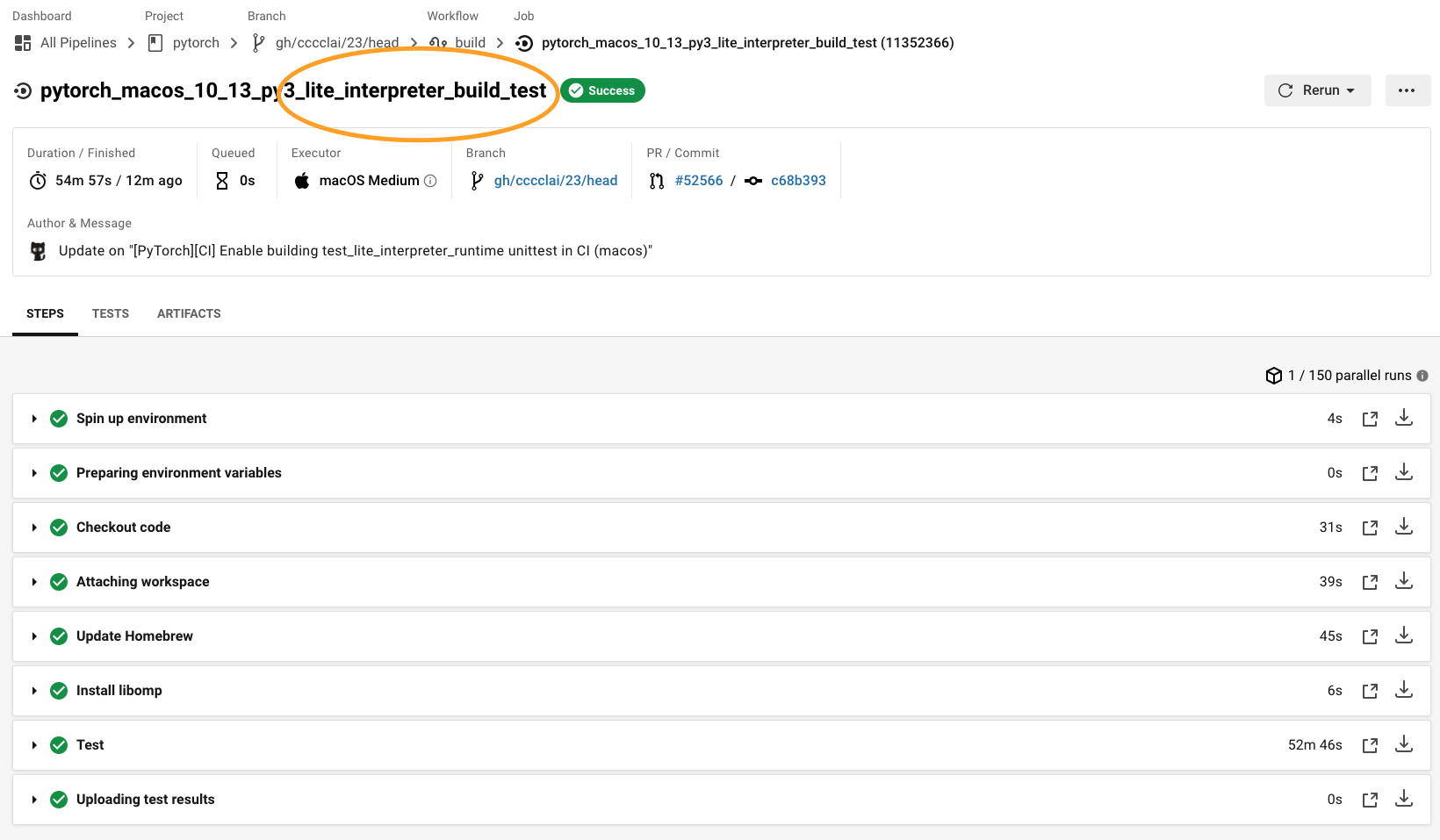 {F467163464} 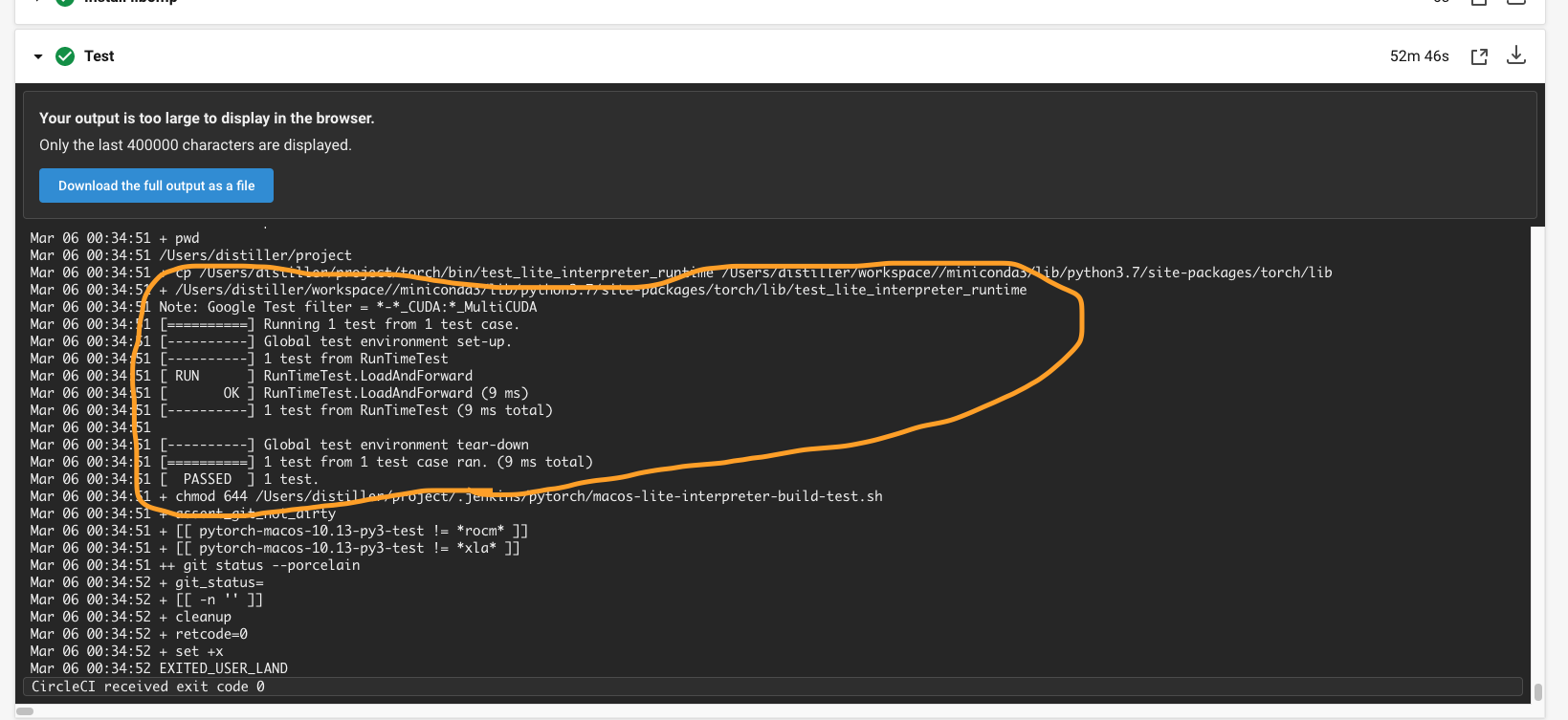 {F467164144} Pull Request resolved: pytorch#52566 Test Plan: Imported from OSS Reviewed By: malfet Differential Revision: D26601585 Pulled By: cccclai fbshipit-source-id: da7f47c906317ab3a4ef38fe2dbf2e89bc5bdb24
{kind=link}
{kind=link}
Summary: Fixes pytorch#52375 Pull Request resolved: pytorch#53088 Reviewed By: zou3519 Differential Revision: D26752772 Pulled By: iramazanli fbshipit-source-id: 21e395c6bbfd8f2cc808ddc12aefb2a426bb50d0
Summary: Pull Request resolved: pytorch#53429 Call the testing ops through dispatcher instead of calling them through `at::native`. Some metal ops can't be called through dispatcher yet. For example, `at::t` will call `at::as_strided` which hasn't been implemented on metal yet. For those ops, we'll skip and call `mpscnn::`directly. We'll convert those ops once we have implemented the missing ops. ghstack-source-id: 123038068 Test Plan: - Sandcastle CI - Circle CI - AIBench/Mobilelab Reviewed By: SS-JIA, AshkanAliabadi Differential Revision: D26683366 fbshipit-source-id: bf130b191046f5d9ac9b544d512bc6cb94f08c09
Summary: This way, we can get S3 test time stats for windows tests as well. Pull Request resolved: pytorch#53387 Reviewed By: samestep Differential Revision: D26893613 Pulled By: janeyx99 fbshipit-source-id: ac59e4406e472c9004eea0aae8a87a23242e3b34
Summary:
Fixes #{issue number}
Pull Request resolved: pytorch#53420
Reviewed By: navahgar
Differential Revision: D26876784
Pulled By: Chillee
fbshipit-source-id: 05e7c782a72de5159879f88a104f1a273e0345eb
… and make ROCM and CUDA OpInfo tests consistent Test Plan: revert-hammer Differential Revision: D26811466 (pytorch@a5ada21) Original commit changeset: 8434a7515d83 fbshipit-source-id: 9c2c760e18154a88cf7531e45843a802e3f3d19c
Summary: Pull Request resolved: pytorch#53524 Add to->to_copy in the ReplaceWithCopy pass for playing well with AliasDb Test Plan: Run bench with CastedBatchOneHot fusion off (https://www.internalfb.com/intern/diff/view-version/123230476/), on adindexer and adfinder models Reviewed By: hlu1 Differential Revision: D26887050 fbshipit-source-id: 3f2fb9e27783bcdeb91c8b4181575f059317aff1
Summary: ref: pytorch#16574 Pull Request resolved: pytorch#52408 Reviewed By: anjali411 Differential Revision: D26654687 Pulled By: malfet fbshipit-source-id: 6feb603d8fb03c2ba2a01468bfde1a9901e889fd
…ultiprocessing to torch/distributed/elastic (pytorch#53574) Summary: Pull Request resolved: pytorch#53574 Upstreams `torchelastic/timer|multiprocessing` to `torch/distributed/elastic/timer|multiprocessing` Test Plan: ``` buck test mode/dev-nosan //caffe2/torch/distributed/elastic/... buck test mode/dev-nosan //caffe2/test/distributed/elastic/... buck test mode/dev-nosan //pytorch/elastic/torchelastic/... buck test mode/dev-nosan //hpc/... buck test mode/dev-nosan //caffe2/torch/fb/training_toolkit/... ``` Reviewed By: borovsky-d, wilson100hong Differential Revision: D26899809 fbshipit-source-id: e6dbc2a78282eac296c262b3206a979e3ef1ff53
…orch#53600) Summary: A number of derived distributions use base distributions in their implementation. We add what we hope is a comprehensive test whether all distributions actually honor skipping validation of arguments in log_prob and then fix the bugs we found. These bugs are particularly cumbersome in PyTorch 1.8 and master when validate_args is turned on by default In addition one might argue that validate_args is not performing as well as it should when the default is not to validate but the validation is turned on in instantiation. Arguably, there is another set of bugs or at least inconsistencies when validation of inputs does not prevent invalid indices in sample validation (when with validation an IndexError is raised in the test). We would encourage the implementors to be more ambitious when validation is turned on and amend sample validation to throw a ValueError for consistency. Pull Request resolved: pytorch#53600 Reviewed By: mrshenli Differential Revision: D26928088 Pulled By: neerajprad fbshipit-source-id: 52784a754da2faee1a922976e2142957c6c02e28
Summary: pytorch#52875 introduced this bug, as `supports_tensor_out` was replaced with `supports_out` in pytorch#53259, so CI checks are failing. Pull Request resolved: pytorch#53745 Reviewed By: gmagogsfm Differential Revision: D26958151 Pulled By: malfet fbshipit-source-id: 7cfe5d1c1a33f06cb8be94281ca98c635df76838
…h#53665) Summary: Pull Request resolved: pytorch#53665 ngimel pointed out to me where we already test the behavior of the `Upsample` ops in `test_nn.py`. This PR deleting my bespoke tests in `test_torch.py` and updates those in `test_nn.py` to test memory format properly. There were two reasons the original test didn't pick up on a memory format regression: - They didn't test the memory format of the output tensor explicitly, i.e. `output.is_contiguous(memory_format=...)` - Even with that change, the test tensors were to simple to fail the tests. From some trial and error, it looks like one of the first two dimensions in the inputs needs to be > 1 in order for the `channels_last` memory format to actually re-order the strides. Test Plan: Imported from OSS Reviewed By: ngimel Differential Revision: D26929683 Pulled By: bdhirsh fbshipit-source-id: d17bc660ff031e9b3e2c93c60a9e9308e56ea612
Summary: Fixes pytorch#51735 Pull Request resolved: pytorch#52175 Reviewed By: mrshenli Differential Revision: D26919193 Pulled By: eellison fbshipit-source-id: d036cbc7b42377f88a3d381e4932a710b8d22a04
Summary: Pull Request resolved: pytorch#53644 Reviewed By: gcatron Differential Revision: D26506841 fbshipit-source-id: 64367d7e9f6619d014a01c147476b50467efa5c8
…rs (pytorch#53210) Summary: Pull Request resolved: pytorch#53210 Test Plan: Imported from OSS Reviewed By: vkuzo Differential Revision: D26791724 fbshipit-source-id: b2a226a22d6aba86dd01cacbb56577048a289b3e
Summary: The test test_collect_shards fails on single GPU setup. Enabling the multi gpu checker. Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com> Pull Request resolved: pytorch#53564 Reviewed By: H-Huang Differential Revision: D26952325 Pulled By: rohan-varma fbshipit-source-id: e8956f9277c7320024bece129767e83fbdf02b2c
) Summary: Pull Request resolved: pytorch#53400 This is a reland of D26617038 (pytorch@b4a8d98) after rebasing onto D26802576 (pytorch@f595ba1). Optimize the blob serialization code by using `AddNAlreadyReserved()` when serializing tensor data, rather than making N separate `Add()` calls. `AddNAlreadyReserved()` is a simple addition operation, while each `Add()` call checks to see if it needs to reserve new space, and then updates the element data, which is unnecessary in this case. ghstack-source-id: 123567030 Test Plan: This appears to improve raw serialization performance by 30 to 35% for float, double, and int64_t types which use this function. This improvement appears relatively consistent across large and small tensor sizes. Reviewed By: mraway Differential Revision: D26853941 fbshipit-source-id: 4ccaa5bc1dd7f7864068d71a0cde210c699cbdba
pytorch#53401) Summary: Pull Request resolved: pytorch#53401 This is a reland of D26641599 (pytorch@cd9ac54) after rebasing onto D26802576 (pytorch@f595ba1). Add some small utility functions to read the blob names back from the minidb file so that we can verify how many chunks were written for each blob. ghstack-source-id: 123567033 Test Plan: buck test caffe2/caffe2/python/operator_test:load_save_test Reviewed By: mraway Differential Revision: D26853942 fbshipit-source-id: 0b45078fdd279f547752c8fdb771e296374a00da
Summary: Pull Request resolved: pytorch#53762 Test Plan: CI. Reviewed By: seemethere Differential Revision: D26961133 Pulled By: samestep fbshipit-source-id: 972ea480baa3f34b65327abdf7e8bfdf30788572
Summary: Pull Request resolved: pytorch#53198 Test Plan: Imported from OSS Reviewed By: nikithamalgifb Differential Revision: D26830030 Pulled By: zdevito fbshipit-source-id: 34d383c4561bba88dee6d570cbd22bd58a3fe856
Summary: Pull Request resolved: pytorch#53749 Split up tests into cases that cover specific functionality. Goals: 1. Avoid the omnibus test file mess (see: test_jit.py) by imposing early structure and deliberately avoiding a generic TestPackage test case. 2. Encourage testing of individual APIs and components by example. 3. Hide the fake modules we created for these tests in their own folder. You can either run the test files individually, or still use test/test_package.py like before. Also this isort + black formats all the tests. Test Plan: Imported from OSS Reviewed By: SplitInfinity Differential Revision: D26958535 Pulled By: suo fbshipit-source-id: 8a63048b95ca71f4f1aa94e53c48442686076034
Summary: Pull Request resolved: pytorch#53596 This description will be used in ddp_comm_hook docstrings. ghstack-source-id: 123590360 Test Plan: waitforbuildbot Reviewed By: rohan-varma Differential Revision: D26908160 fbshipit-source-id: 824dea9203ca583676bddf0161c9edca52c9d20e
…torch#53253) Summary: Pull Request resolved: pytorch#53253 Since GradBucket class becomes public, mention this class in ddp_comm_hooks.rst. Screenshot: {F478201008} ghstack-source-id: 123596842 Test Plan: viewed generated html file Reviewed By: rohan-varma Differential Revision: D26812210 fbshipit-source-id: 65b70a45096b39f7d41a195e65b365b722645000
…ytorch#53613) Summary: When calling `TensorIterator::for_each` with a 1d loop, it creates a `function_ref` for the 1D iteration, then wraps it with `LOOP_WRAPPER` to transform it into a 2d loop. That 2d loop then gets wrapped in another `function_ref`. This can result in significant overhead if the 1d inner loop is over a small number of elements. Instead, this wraps the 1d loop before type-erasure so only one level of `function_ref` is introduced. A simple benchmark demonstrates this is a win: ```python import torch a = torch.rand((10000, 2))[::2] %timeit a + a ``` Note the 2D tensor cannot be coalesced into 1D and both `cpu_kernel` and `cpu_kernel_vec` use 1D for_each. On master, this takes 42 us but with this change it's down to 32us. Pull Request resolved: pytorch#53613 Reviewed By: VitalyFedyunin Differential Revision: D26947143 Pulled By: ezyang fbshipit-source-id: 5189ada0d82bbf74170fb446763753f02478abf6
Summary: Fixes pytorch#50002 The last commit adds tests for 3d conv with the `SubModelFusion` and `SubModelWithoutFusion` classes. Pull Request resolved: pytorch#50003 Reviewed By: mrshenli Differential Revision: D26325953 Pulled By: jerryzh168 fbshipit-source-id: 7406dd2721c0c4df477044d1b54a6c5e128a9034
pytorch#53330) Summary: Pull Request resolved: pytorch#53330 Fixed a condition check for fixed qparam ops, previously we were including CopyNodes as well Test Plan: python test/test_quantization.py TestQuantizeFxOps.test_fixed_qparams_ops_fp16 Imported from OSS Reviewed By: vkuzo Differential Revision: D26836867 fbshipit-source-id: 8c486155244f852e675a938c3f4237f26505671c
* added compareSet method for HashStore class * reverted the debug code in the HashStore test file * added compareSet method for FileStore and added testcase * reverting debug changes Co-authored-by: Siva-Datta.Mannava <VD9ZG3@Siva-DattaMannavas-MacBook-Pro.local>
…_compare_set method in python API tests to common StoreTestBase class
siva1007
added a commit
that referenced
this pull request
Mar 11, 2021
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Rebased with viable/strict and skipping the HashStoreTest for win32