Remove optional for veiw_fn during View Tracking#50067
Remove optional for veiw_fn during View Tracking#50067ejguan wants to merge 7 commits intogh/ejguan/18/basefrom
Conversation
[ghstack-poisoned]
💊 CI failures summary and remediationsAs of commit 31b2a5f (more details on the Dr. CI page): 💚 💚 Looks good so far! There are no failures yet. 💚 💚 This comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions to the (internal) Dr. CI Users group. |
Fixes #49257 Using the following script to test the performance. ```python import torch x = torch.randn(100, 100, requires_grad=True) with torch.autograd.profiler.profile() as prof: for _ in range(100): y = torch.sum(torch.diagonal(x)) y.backward() print(prof.key_averages().table(sort_by="self_cpu_time_total")) ``` ### Nightly 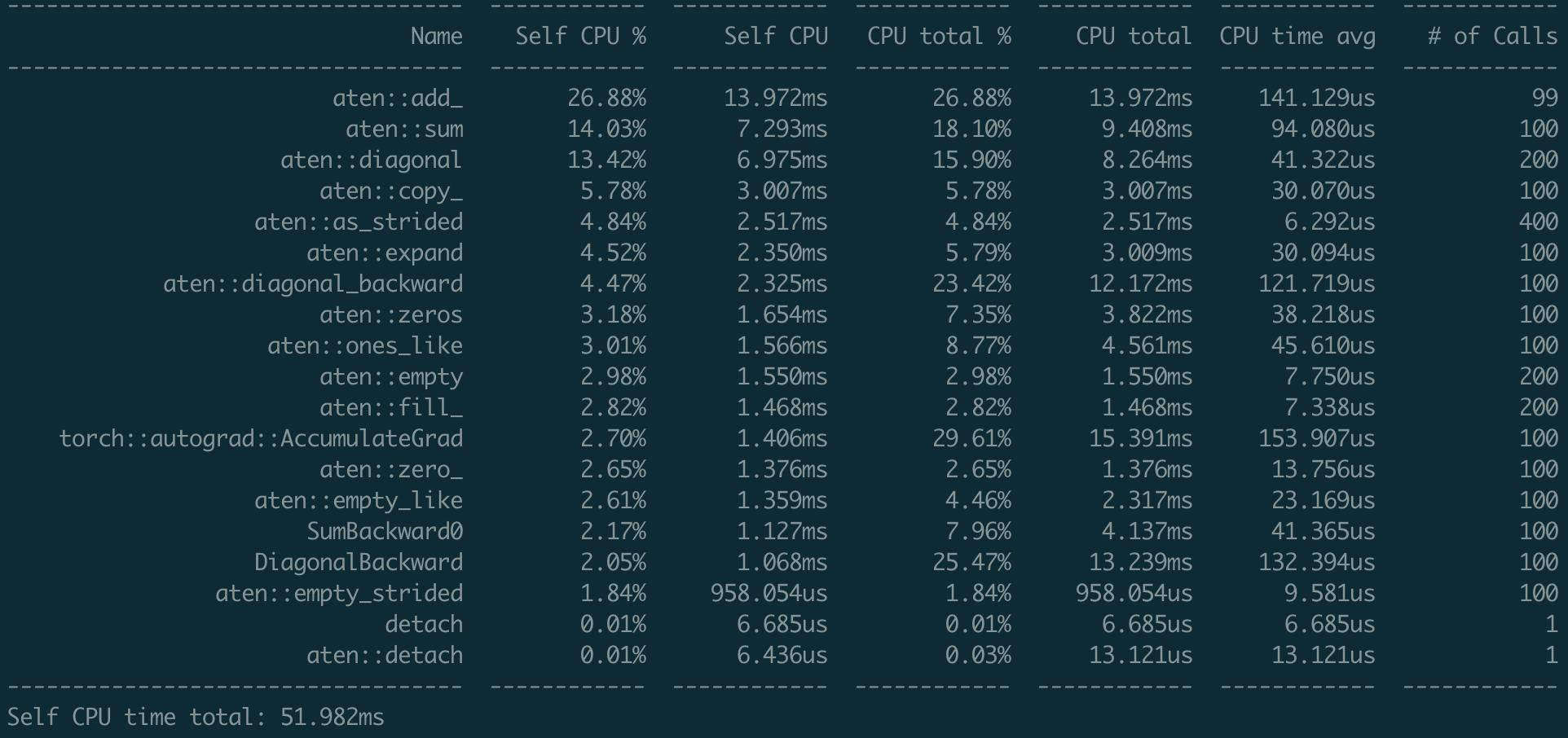 ### Current 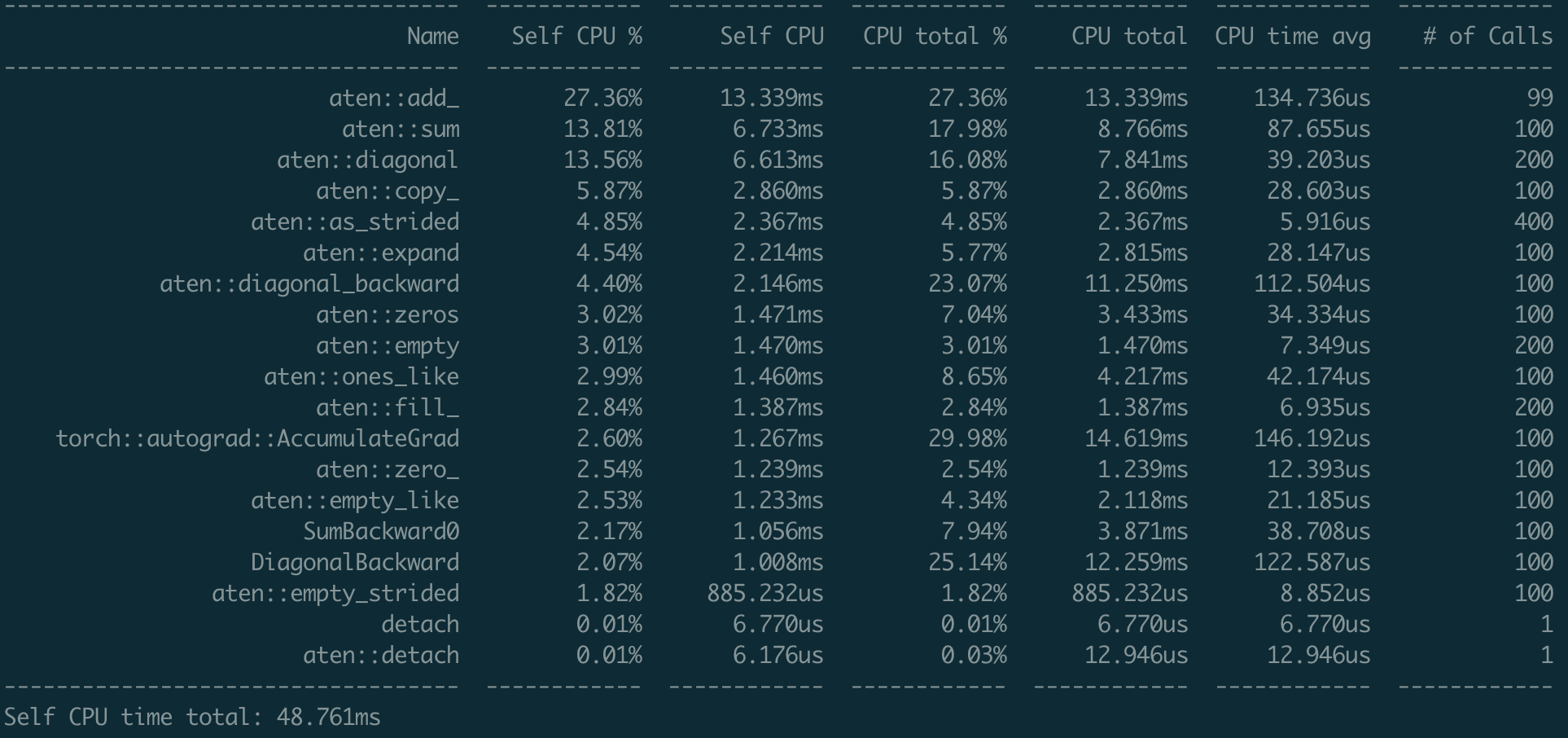 I don't find any significant regression over backward function (using the `view_fn`) Differential Revision: [D25768847](https://our.internmc.facebook.com/intern/diff/D25768847) [ghstack-poisoned]
{kind=link}
{kind=link}
Codecov Report
@@ Coverage Diff @@
## gh/ejguan/18/base #50067 +/- ##
=====================================================
- Coverage 80.70% 80.70% -0.01%
=====================================================
Files 1905 1905
Lines 206813 206811 -2
=====================================================
- Hits 166916 166912 -4
- Misses 39897 39899 +2 |
 albanD
left a comment
albanD
left a comment
There was a problem hiding this comment.
This change looks good.
Can you check the perf implication with the new Timer class (https://pytorch.org/docs/master/benchmark_utils.html?highlight=timer#torch.utils.benchmark.Timer) with the instruction count mode that will be much more precise!
You can do somthing like this to save a trace (here for a basic view op, but maybe something else if it is more relevant to your PR):
import torch
from torch.utils.benchmark import Timer
timer = Timer("x.view(-1);", setup="torch::Tensor x = torch::ones({1,2,3});", language="c++")
res = timer.collect_callgrind(number=10)
torch.save(res, "save.pth")And once you do that for master and your branch, you can compare with:
import torch
torch.set_printoptions(linewidth=260)
master_instr = torch.load("master.pth")
fast_view_instr = torch.load("fast_view.pth")
master_instr = master_instr.as_standardized()
fast_view_instr = fast_view_instr.as_standardized()
print(master_instr)
print(fast_view_instr)
delta = fast_view_instr.delta(master_instr).denoise()
print(delta)Fixes #49257 Using the following script to test the performance. ```python import torch x = torch.randn(100, 100, requires_grad=True) with torch.autograd.profiler.profile() as prof: for _ in range(100): y = torch.sum(torch.diagonal(x)) y.backward() print(prof.key_averages().table(sort_by="self_cpu_time_total")) ``` ### Nightly 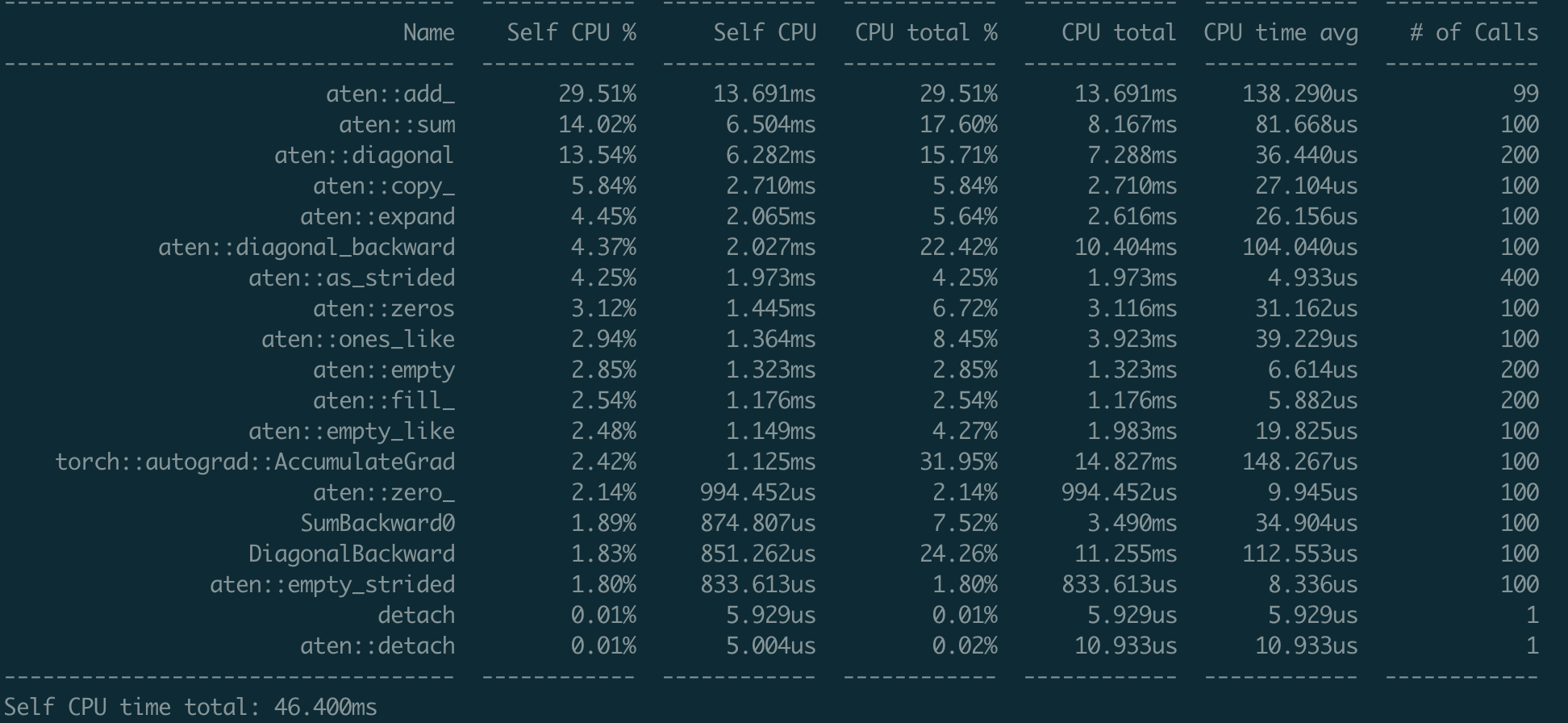 ### Current 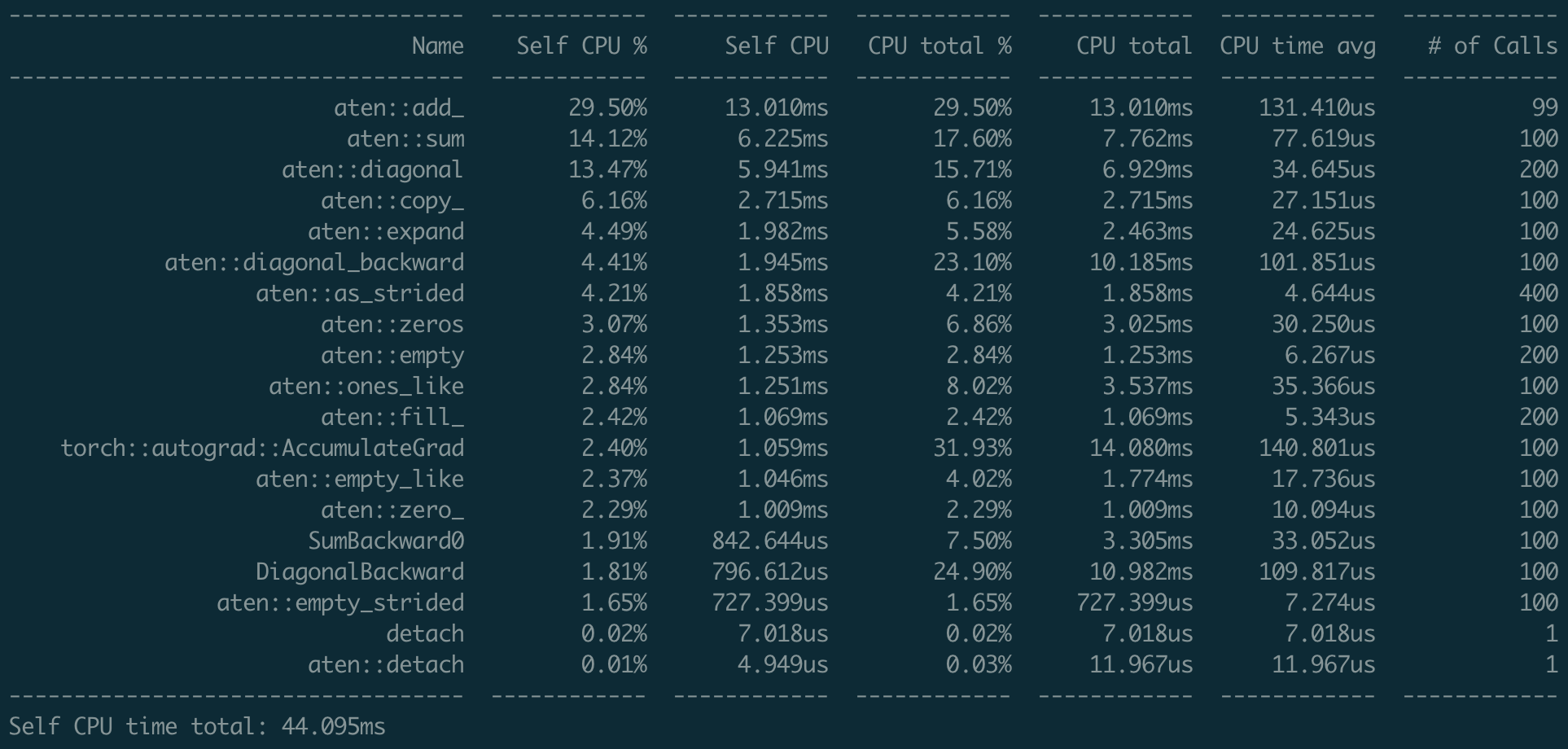 I don't find any significant regression over backward function (using the `view_fn`) Differential Revision: [D25768847](https://our.internmc.facebook.com/intern/diff/D25768847) [ghstack-poisoned]
{kind=link}
{kind=link}
Fixes #49257 Using the following script to test the performance. ```python import torch x = torch.randn(100, 100, requires_grad=True) with torch.autograd.profiler.profile() as prof: for _ in range(100): y = torch.sum(torch.diagonal(x)) y.backward() print(prof.key_averages().table(sort_by="self_cpu_time_total")) ``` ### Nightly  ### Current  I don't find any significant regression over backward function (using the `view_fn`) Differential Revision: [D25768847](https://our.internmc.facebook.com/intern/diff/D25768847) [ghstack-poisoned]
Fixes #49257 Using the `Callgrind` to test the performance. ```python import torch import timeit from torch.utils.benchmark import Timer timer = Timer("x.view({100, 5, 20});", setup="torch::Tensor x = torch::ones({10, 10, 100});", language="c++", timer=timeit.default_timer) res = timer.collect_callgrind(number=10) ``` ### Nightly ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f7949138c40> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42310 42310 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Current ```python <torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f78f271a580> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42480 42480 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Compare There are 170 instructions reduced ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f7941b7a7c0> 970 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool) 240 ???:torch::autograd::ViewInfo::~ViewInfo() 180 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, std::function<at::Tensor (at::Tensor const&)>) 130 ???:torch::autograd::make_variable_differentiable_view(at::Tensor const&, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta, bool) 105 /tmp/benchmark_utils_jit_build_69e2f1710544485588feeca0719a3a57/timer_cpp_4435526292782672407/timer_src.cpp:main 100 ???:std::function<at::Tensor (at::Tensor const&)>::function(std::function<at::Tensor (at::Tensor const&)> const&) 70 ???:torch::autograd::DifferentiableViewMeta::~DifferentiableViewMeta() 70 ???:torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta(c10::TensorImpl*, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta) -100 ???:c10::optional_base<torch::autograd::ViewInfo>::optional_base(c10::optional_base<torch::autograd::ViewInfo>&&) -105 /tmp/benchmark_utils_jit_build_2e75f38b553e42eba00523a86ad9aa05/timer_cpp_3360771523810516633/timer_src.cpp:main -120 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, c10::optional<std::function<at::Tensor (at::Tensor const&)> >) -210 ???:c10::optional_base<std::function<at::Tensor (at::Tensor const&)> >::~optional_base() -240 ???:c10::optional_base<torch::autograd::ViewInfo>::~optional_base() -920 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, c10::optional<std::function<at::Tensor (at::Tensor const&)> >, torch::autograd::CreationMeta, bool) ``` Differential Revision: [D25768847](https://our.internmc.facebook.com/intern/diff/D25768847) [ghstack-poisoned]
Fixes #49257 Using the `Callgrind` to test the performance. ```python import torch import timeit from torch.utils.benchmark import Timer timer = Timer("x.view({100, 5, 20});", setup="torch::Tensor x = torch::ones({10, 10, 100});", language="c++", timer=timeit.default_timer) res = timer.collect_callgrind(number=10) ``` ### Nightly ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f7949138c40> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42310 42310 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Current ```python <torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f78f271a580> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42480 42480 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Compare There are 170 instructions reduced ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f7941b7a7c0> 970 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool) 240 ???:torch::autograd::ViewInfo::~ViewInfo() 180 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, std::function<at::Tensor (at::Tensor const&)>) 130 ???:torch::autograd::make_variable_differentiable_view(at::Tensor const&, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta, bool) 105 /tmp/benchmark_utils_jit_build_69e2f1710544485588feeca0719a3a57/timer_cpp_4435526292782672407/timer_src.cpp:main 100 ???:std::function<at::Tensor (at::Tensor const&)>::function(std::function<at::Tensor (at::Tensor const&)> const&) 70 ???:torch::autograd::DifferentiableViewMeta::~DifferentiableViewMeta() 70 ???:torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta(c10::TensorImpl*, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta) -100 ???:c10::optional_base<torch::autograd::ViewInfo>::optional_base(c10::optional_base<torch::autograd::ViewInfo>&&) -105 /tmp/benchmark_utils_jit_build_2e75f38b553e42eba00523a86ad9aa05/timer_cpp_3360771523810516633/timer_src.cpp:main -120 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, c10::optional<std::function<at::Tensor (at::Tensor const&)> >) -210 ???:c10::optional_base<std::function<at::Tensor (at::Tensor const&)> >::~optional_base() -240 ???:c10::optional_base<torch::autograd::ViewInfo>::~optional_base() -920 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, c10::optional<std::function<at::Tensor (at::Tensor const&)> >, torch::autograd::CreationMeta, bool) ``` [ghstack-poisoned]
Fixes #49257 Using the `Callgrind` to test the performance. ```python import torch import timeit from torch.utils.benchmark import Timer timer = Timer("x.view({100, 5, 20});", setup="torch::Tensor x = torch::ones({10, 10, 100});", language="c++", timer=timeit.default_timer) res = timer.collect_callgrind(number=10) ``` ### Nightly ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f7949138c40> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42310 42310 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Current ```python <torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f78f271a580> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42480 42480 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Compare There are 170 instructions reduced ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f7941b7a7c0> 970 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool) 240 ???:torch::autograd::ViewInfo::~ViewInfo() 180 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, std::function<at::Tensor (at::Tensor const&)>) 130 ???:torch::autograd::make_variable_differentiable_view(at::Tensor const&, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta, bool) 105 /tmp/benchmark_utils_jit_build_69e2f1710544485588feeca0719a3a57/timer_cpp_4435526292782672407/timer_src.cpp:main 100 ???:std::function<at::Tensor (at::Tensor const&)>::function(std::function<at::Tensor (at::Tensor const&)> const&) 70 ???:torch::autograd::DifferentiableViewMeta::~DifferentiableViewMeta() 70 ???:torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta(c10::TensorImpl*, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta) -100 ???:c10::optional_base<torch::autograd::ViewInfo>::optional_base(c10::optional_base<torch::autograd::ViewInfo>&&) -105 /tmp/benchmark_utils_jit_build_2e75f38b553e42eba00523a86ad9aa05/timer_cpp_3360771523810516633/timer_src.cpp:main -120 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, c10::optional<std::function<at::Tensor (at::Tensor const&)> >) -210 ???:c10::optional_base<std::function<at::Tensor (at::Tensor const&)> >::~optional_base() -240 ???:c10::optional_base<torch::autograd::ViewInfo>::~optional_base() -920 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, c10::optional<std::function<at::Tensor (at::Tensor const&)> >, torch::autograd::CreationMeta, bool) ``` [ghstack-poisoned]
|
@albanD |
|
Hi, Thanks for the benchmark, after discussing with other people, it is expected that the runtime is the same (the compiler is too smart for us): https://godbolt.org/z/W16xos (thanks @swolchok for the godbolt link). |
albanD
left a comment
There was a problem hiding this comment.
The updated code looks good to me, thanks!
Summary: Pull Request resolved: pytorch#50067 Fixes pytorch#49257 Using the `Callgrind` to test the performance. ```python import torch import timeit from torch.utils.benchmark import Timer timer = Timer("x.view({100, 5, 20});", setup="torch::Tensor x = torch::ones({10, 10, 100});", language="c++", timer=timeit.default_timer) res = timer.collect_callgrind(number=10) ``` ### Nightly ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f7949138c40> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42310 42310 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Current ```python <torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.CallgrindStats object at 0x7f78f271a580> x.view({100, 5, 20}); setup: torch::Tensor x = torch::ones({10, 10, 100}); All Noisy symbols removed Instructions: 42480 42480 Baseline: 0 0 10 runs per measurement, 1 thread Warning: PyTorch was not built with debug symbols. Source information may be limited. Rebuild with REL_WITH_DEB_INFO=1 for more detailed results. ``` ### Compare There are 170 instructions reduced ```python torch.utils.benchmark.utils.valgrind_wrapper.timer_interface.FunctionCounts object at 0x7f7941b7a7c0> 970 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, std::function<at::Tensor (at::Tensor const&)>, torch::autograd::CreationMeta, bool) 240 ???:torch::autograd::ViewInfo::~ViewInfo() 180 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, std::function<at::Tensor (at::Tensor const&)>) 130 ???:torch::autograd::make_variable_differentiable_view(at::Tensor const&, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta, bool) 105 /tmp/benchmark_utils_jit_build_69e2f1710544485588feeca0719a3a57/timer_cpp_4435526292782672407/timer_src.cpp:main 100 ???:std::function<at::Tensor (at::Tensor const&)>::function(std::function<at::Tensor (at::Tensor const&)> const&) 70 ???:torch::autograd::DifferentiableViewMeta::~DifferentiableViewMeta() 70 ???:torch::autograd::DifferentiableViewMeta::DifferentiableViewMeta(c10::TensorImpl*, c10::optional<torch::autograd::ViewInfo>, c10::optional<torch::autograd::ViewInfo>, torch::autograd::CreationMeta) -100 ???:c10::optional_base<torch::autograd::ViewInfo>::optional_base(c10::optional_base<torch::autograd::ViewInfo>&&) -105 /tmp/benchmark_utils_jit_build_2e75f38b553e42eba00523a86ad9aa05/timer_cpp_3360771523810516633/timer_src.cpp:main -120 ???:torch::autograd::ViewInfo::ViewInfo(at::Tensor, c10::optional<std::function<at::Tensor (at::Tensor const&)> >) -210 ???:c10::optional_base<std::function<at::Tensor (at::Tensor const&)> >::~optional_base() -240 ???:c10::optional_base<torch::autograd::ViewInfo>::~optional_base() -920 ???:torch::autograd::as_view(at::Tensor const&, at::Tensor const&, bool, bool, c10::optional<std::function<at::Tensor (at::Tensor const&)> >, torch::autograd::CreationMeta, bool) ``` Test Plan: Imported from OSS Reviewed By: albanD Differential Revision: D25900495 Pulled By: ejguan fbshipit-source-id: dedd30e69db6b48601a18ae98d6b28faeae30d90
Fixes #49257
Stack from ghstack:
Using the
Callgrindto test the performance.Nightly
Current
Compare
There are 170 instructions added
Differential Revision: D25900495