colexec: add unordered distinct#42522
Conversation
|
This change is |
|
The benchmarks: |
5955279 to
4e64c23
Compare
 yuzefovich
left a comment
yuzefovich
left a comment
There was a problem hiding this comment.
Reviewable status:
complete! 0 of 0 LGTMs obtained (waiting on @asubiotto)
pkg/col/coldata/vec_tmpl.go, line 71 at r2 (raw file):
toCol = execgen.SLICE(toCol, 0, int(args.DestIdx)) // {{if eq .LTyp.String "Bytes"}} maxIdx := uint16(0)
I don't really like this solution, but it is least "invasive." I think that we want to have special casing for NULL vs non-NULL case, and possibly we might get rid off maybeBackfillOffsets method of Bytes then (this is TBD).
4e64c23 to
e599d1b
Compare
|
The problem with NULLs in |
e599d1b to
2354040
Compare
|
Friendly ping. |
8ce052a to
c283edc
Compare
yuzefovich
left a comment
There was a problem hiding this comment.
Reviewable status:
pkg/sql/opt/exec/execbuilder/testdata/aggregate, line 954 at r4 (raw file):
---- · distributed false · · · vectorized false · ·
Note that these queries are no longer executed via the vectorized engine because now we have a non-streaming operator (newly introduced unordered distinct) whereas previously we were wrapping a distinct processor (and all wrapped processors are considered streaming).
 jordanlewis
left a comment
jordanlewis
left a comment
There was a problem hiding this comment.
Reviewable status:
pkg/sql/colexec/distinct_test.go, line 110 at r4 (raw file):
runTests(t, []tuples{tc.tuples}, tc.expected, unorderedVerifier, func(input []Operator) (Operator, error) { return NewUnorderedDistinct(testAllocator, input[0], tc.distinctCols, tc.colTypes), nil
I think it would be nice if this test clause would actually mix up the tuples to be unordered, but maybe it's not important.
pkg/sql/colexec/execplan.go, line 605 at r4 (raw file):
return result, err } // TODO(yuzefovich): implement the distinct on partially ordered columns.
Can you open an issue for this? It's a nice self contained project.
pkg/sql/colexec/unordered_distinct.go, line 107 at r4 (raw file):
// Since next is no longer useful and pre-allocated to the appropriate // size, we can use it as the selection vector. This way we don't have to // reallocate a huge array.
Nice!
pkg/sql/colexec/unordered_distinct.go, line 110 at r4 (raw file):
op.sel = op.ht.next for _, keyID := range op.ht.first {
Hmm doesn't this undercount in the case of hash collisions? I forget how this works, but I thought that you have to traverse the whole chain to check equality as well.
pkg/sql/opt/exec/execbuilder/testdata/aggregate, line 954 at r4 (raw file):
Previously, yuzefovich wrote…
Note that these queries are no longer executed via the vectorized engine because now we have a non-streaming operator (newly introduced unordered distinct) whereas previously we were wrapping a distinct processor (and all wrapped processors are considered streaming).
Ack.
c283edc to
41293e5
Compare
yuzefovich
left a comment
There was a problem hiding this comment.
Reviewable status:
pkg/sql/colexec/distinct_test.go, line 110 at r4 (raw file):
Previously, jordanlewis (Jordan Lewis) wrote…
I think it would be nice if this test clause would actually mix up the tuples to be unordered, but maybe it's not important.
Hm, I think it's not that important. This is more like sanity-check test, it can be very easy.
pkg/sql/colexec/execplan.go, line 605 at r4 (raw file):
Previously, jordanlewis (Jordan Lewis) wrote…
Can you open an issue for this? It's a nice self contained project.
Done.
I was thinking of this TODO as the necessary part before closing #39240, and actually I started working on it right after. Maybe I'll pick it back up soon.
pkg/sql/colexec/unordered_distinct.go, line 107 at r4 (raw file):
Previously, jordanlewis (Jordan Lewis) wrote…
Nice!
I copied this approach from hash_aggregator.go (so kudos to Angela).
pkg/sql/colexec/unordered_distinct.go, line 110 at r4 (raw file):
Previously, jordanlewis (Jordan Lewis) wrote…
Hmm doesn't this undercount in the case of hash collisions? I forget how this works, but I thought that you have to traverse the whole chain to check equality as well.
You're totally right - nice catch! I added TestDistinctAgainstProcessor, and it caught this problem right away. I'll have to spend a little bit more time on this (I might delay fixing this until I'm working on spilling for hash joiner).
ff144d5 to
104d1e8
Compare
|
I understand that this PR is not ready for another review? Let me know if that changes. |
|
Yeah, it has a bug at the moment, so not RFAL. |
104d1e8 to
2cb8a51
Compare
|
Alright, this guy is RFAL. |
f3e1a69 to
2159b65
Compare
 asubiotto
left a comment
asubiotto
left a comment
There was a problem hiding this comment.
Reviewed 15 of 15 files at r5, 1 of 1 files at r6, 1 of 1 files at r7, 11 of 11 files at r8, 1 of 1 files at r9, 2 of 2 files at r10.
Reviewable status:
pkg/sql/colexec/hashjoiner_tmpl.go, line 113 at r7 (raw file):
continue } else if probeIsNull { ht.differs[toCheck] = true
I would probably write this:
if probeIsNull {
if !buildIsNull {
ht.differs[toCheck] = true
}
continue
}
And maybe add a comment to the ht.differs[toCheck]? I think this code could generally use more comments.
pkg/sql/colexec/unordered_distinct.go, line 102 at r8 (raw file):
if !op.buildFinished { op.buildFinished = true op.builder.exec(ctx)
Doing this naively will store every single tuple in the hash table right? That seems unnecessarily memory-intensive. Is there a way we can modify the hash table to only keep the first tuple? Will this affect performance? Seems like we're skipping the rest in head below anyway.
pkg/sql/colexec/unordered_distinct.go, line 138 at r8 (raw file):
toCol := op.output.ColVec(i) fromCol := op.ht.vals.colVecs[colIdx] toCol.Copy(
Should this be wrapped in a PerformOperation? Don't we have a lint rule that enforces this?
pkg/sql/colexec/unordered_distinct.go, line 146 at r8 (raw file):
SrcEndIdx: batchEnd, }, Sel64: op.sel,
Does this op.sel need to be "advanced" for the next iteration? If so, would this be caught by randomizing the batch size?
pkg/sql/distsql/columnar_operators_test.go, line 130 at r5 (raw file):
seed := rand.Int() rng := rand.New(rand.NewSource(int64(seed)))
Why is this not randutil.NewPseudoRand?
pkg/sql/distsql/columnar_operators_test.go, line 140 at r5 (raw file):
} for run := 1; run < nRuns; run++ {
<=?
pkg/sql/distsql/columnar_operators_test.go, line 193 at r5 (raw file):
} if err := verifyColOperator( true, /* anyOrder */
Not sure if I said this before, but we should probably extract these arguments out into a struct.
pkg/sql/distsql/columnar_utils_test.go, line 50 at r10 (raw file):
memoryLimit int64, ) error { const floatPrecision = 0.0000001
I'm not sure why the addition of NULLs to grouping columns affected this?
Release note: None
This commit removes some extra empty lines from the generated code by appending `-` to the end of the template definitions. Also, it refactors one conditional into an assignment. Release note: None
Previously we incorrectly were handling the case of allowed null equality in the hash table (which is used by the hash grouper and unordered distinct) - we were resetting groupID of the tuple on the probe side of that tuple has NULL value in the equality column whereas the build tuple has a non-NULL value. This could result in incorrectly populated `same` array and is now fixed. Release note: None
This commit adds an unordered distinct operator. The operator simply builds a hashTable on the first call to Next() on the whole input, then iterates over all of the tuples to check whether the tuple is the "head" of a linked list that contain all of the tuples that are equal on distinct columns. Only the "head" is included into the big selection vector. Once the big selection vector is populated, the operator proceeds to returning the batches according to a chunk of the selection vector. This doesn't take into account whether the input is partially ordered, and this item is left as a follow-up work. Release note (sql change): vectorized execution engine now supports DISTINCT on unordered input.
Previously, hash grouper could hit an internal error of index outside of range when it was looking for the "head" of a linked list. Now this is fixed by refactoring the code in question. I think the code is now more comprehensible. There is no release note since hash grouper so far has been used only with `experimental_on`. Release note: None
This commit adds an ability to insert NULL values into grouping columns and increases the number of grouping columns tested (previously it was hard-coded as one). ANY_NOT_NULL aggregate is now skipped since it returns non-deterministic output. This change required modifications to the test harness to allow the results of aggregation to deviate slightly when operating on float values because direct string matching will not work in some cases. Also, this commit extracts out arguments to the test harness into a separate struct. Release note: None
2159b65 to
1e2327b
Compare
yuzefovich
left a comment
There was a problem hiding this comment.
Reviewable status:
pkg/sql/colexec/hashjoiner_tmpl.go, line 113 at r7 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
I would probably write this:
if probeIsNull { if !buildIsNull { ht.differs[toCheck] = true } continue }And maybe add a comment to the
ht.differs[toCheck]? I think this code could generally use more comments.
I think keeping two ifs separate is easier to understand. Added a couple of comments. In general, my understanding of this code is not great though :/
pkg/sql/colexec/unordered_distinct.go, line 102 at r8 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Doing this naively will store every single tuple in the hash table right? That seems unnecessarily memory-intensive. Is there a way we can modify the hash table to only keep the first tuple? Will this affect performance? Seems like we're skipping the rest in
headbelow anyway.
Yes, as we discussed, the whole input is stored in the hash table, and only head values will be output. It is inefficient but should be addressed separately as a follow-up work.
pkg/sql/colexec/unordered_distinct.go, line 138 at r8 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Should this be wrapped in a
PerformOperation? Don't we have a lint rule that enforces this?
Yes, good catch. I think I wrote it initially before we had memory monitoring in place.
No, we don't have linters for Vec.Append and Vec.Copy calls (only for creating batches, creating and appending columns) because it'll be hard to come up with a regex that would enforce it. It could work if we were to name the variables the same way throughout colexec package. Previously, I simply went over all usages of Copy and Append and made sure that they are accounted for.
pkg/sql/colexec/unordered_distinct.go, line 146 at r8 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Does this
op.selneed to be "advanced" for the next iteration? If so, would this be caught by randomizing the batch size?
No, it is not needed. We populate op.sel on the first call to Next() for all batches to be output, and then we copy only a slice of it ([op.outputBatchStart, batchEnd]). I think it would have been caught by the tests if there were a bug with this.
pkg/sql/distsql/columnar_operators_test.go, line 130 at r5 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Why is this not
randutil.NewPseudoRand?
For ease of reproduction of the test failures. I think at some point I was using randutil.NewPseudoRand and had a failure that I couldn't reproduce for some reason. I started generating seed locally in these tests and never had such a problem afterwards. The seed is always printed out right in the failure.
pkg/sql/distsql/columnar_operators_test.go, line 140 at r5 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
<=?
Thanks, I think more idiomatic is to start from 0 instead :)
pkg/sql/distsql/columnar_operators_test.go, line 193 at r5 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Not sure if I said this before, but we should probably extract these arguments out into a struct.
Done.
pkg/sql/distsql/columnar_utils_test.go, line 50 at r10 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
I'm not sure why the addition of
NULLs to grouping columns affected this?
It's not the addition of NULLs that prompted this change, but the enhancement of the aggregator test. It actually could happen previously, but it wasn't very likely, and now it became more likely, so I hit it a couple of times out of like 10k runs.
asubiotto
left a comment
There was a problem hiding this comment.
Reviewed 14 of 14 files at r11, 1 of 1 files at r12, 1 of 1 files at r13, 11 of 11 files at r14, 1 of 1 files at r15, 2 of 2 files at r16.
Reviewable status:
pkg/sql/colexec/unordered_distinct.go, line 102 at r8 (raw file):
Previously, yuzefovich wrote…
Yes, as we discussed, the whole input is stored in the hash table, and only
headvalues will be output. It is inefficient but should be addressed separately as a follow-up work.
Could you create an issue for it?
pkg/sql/colexec/unordered_distinct.go, line 138 at r8 (raw file):
Previously, yuzefovich wrote…
Yes, good catch. I think I wrote it initially before we had memory monitoring in place.
No, we don't have linters for
Vec.AppendandVec.Copycalls (only for creating batches, creating and appending columns) because it'll be hard to come up with a regex that would enforce it. It could work if we were to name the variables the same way throughoutcolexecpackage. Previously, I simply went over all usages ofCopyandAppendand made sure that they are accounted for.
Hmm, I wonder what we could do here, it seems like it's easy for something to slip through the cracks.
pkg/sql/distsql/columnar_operators_test.go, line 130 at r5 (raw file):
Previously, yuzefovich wrote…
For ease of reproduction of the test failures. I think at some point I was using
randutil.NewPseudoRandand had a failure that I couldn't reproduce for some reason. I started generatingseedlocally in these tests and never had such a problem afterwards. The seed is always printed out right in the failure.
That seems like something we should look into.
yuzefovich
left a comment
There was a problem hiding this comment.
TFTRs!
bors r+
Reviewable status:
pkg/sql/colexec/unordered_distinct.go, line 102 at r8 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Could you create an issue for it?
Done #44404
pkg/sql/colexec/unordered_distinct.go, line 138 at r8 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
Hmm, I wonder what we could do here, it seems like it's easy for something to slip through the cracks.
I don't have any ideas at the moment :/
pkg/sql/distsql/columnar_operators_test.go, line 130 at r5 (raw file):
Previously, asubiotto (Alfonso Subiotto Marqués) wrote…
That seems like something we should look into.
I don't see it as a big deal. Maybe some time down the line in stabilization period.
42522: colexec: add unordered distinct r=yuzefovich a=yuzefovich **distsql: add a test comparing distinct operator and processor** Release note: None **colexec: minor cleanup of hashjoiner_tmpl** This commit removes some extra empty lines from the generated code by appending `-` to the end of the template definitions. Also, it refactors one conditional into an assignment. Release note: None **colexec: fix a bug in hash table when null equality is allowed** Previously we incorrectly were handling the case of allowed null equality in the hash table (which is used by the hash grouper and unordered distinct) - we were resetting groupID of the tuple on the probe side of that tuple has NULL value in the equality column whereas the build tuple has a non-NULL value. This could result in incorrectly populated `same` array and is now fixed. Release note: None **colexec: add unordered distinct** This commit adds an unordered distinct operator. The operator simply builds a hashTable on the first call to Next() on the whole input, then iterates over all of the tuples to check whether the tuple is the "head" of a linked list that contain all of the tuples that are equal on distinct columns. Only the "head" is included into the big selection vector. Once the big selection vector is populated, the operator proceeds to returning the batches according to a chunk of the selection vector. This doesn't take into account whether the input is partially ordered, and this item is left as a follow-up work. Fixes: #39240. Release note (sql change): vectorized execution engine now supports DISTINCT on unordered input. **colexec: fix hash grouper** Previously, hash grouper could hit an internal error of index outside of range when it was looking for the "head" of a linked list. Now this is fixed by refactoring the code in question. I think the code is now more comprehensible. There is no release note since hash grouper so far has been used only with `experimental_on`. Release note: None **distsql: enhance testing columnar aggregator against processor** This commit adds an ability to insert NULL values into grouping columns and increases the number of grouping columns tested (previously it was hard-coded as one). ANY_NOT_NULL aggregate is now skipped since it returns non-deterministic output. This change required modifications to the test harness to allow the results of aggregation to deviate slightly when operating on float values because direct string matching will not work in some cases. Also, this commit extracts out arguments to the test harness into a separate struct. Release note: None 43288: ui: network latency page r=dhartunian a=elkmaster created new menu item for network latencies reports, redesign, added sort-by and filtering features Resolves: #43206 Release note (ui): none 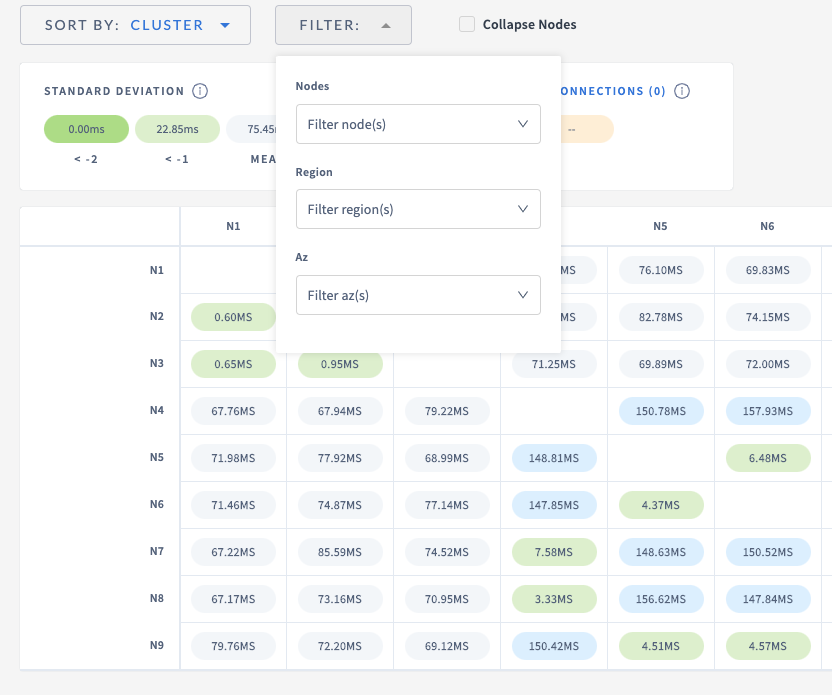 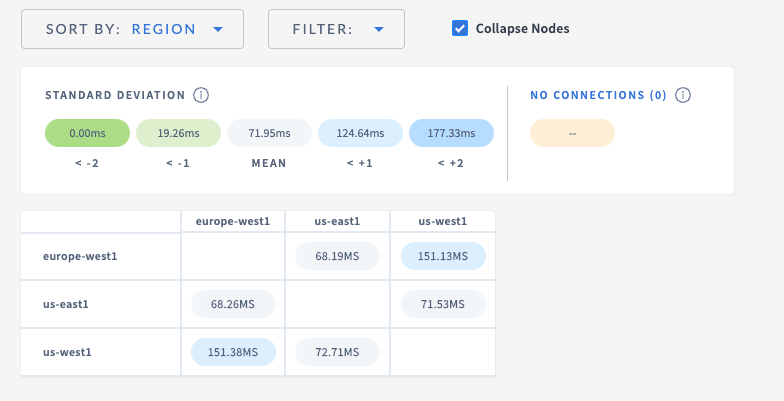 44365: roachtest: adjust tpchvec test r=yuzefovich a=yuzefovich This commit adds the print out of all vec ON and vec OFF times if the test is failed because of slow vec ON performance. Also, in order to reduce noise, we now require that the best vec ON time is worse than the best vec OFF time. This addresses a case when a query has two fast runtimes and two slow ones (I don't know why it happens, but sometimes the first two runs of a query, especially with a small order number like Q3, will be slow with vec ON). Fixes: #44331. Release note: None Co-authored-by: Yahor Yuzefovich <yahor@cockroachlabs.com> Co-authored-by: Vlad <carrott9@gmail.com> Co-authored-by: Vlad Los <carrott9@gmail.com>
{kind=link}
{kind=link}
Build succeeded |
distsql: add a test comparing distinct operator and processor
Release note: None
colexec: minor cleanup of hashjoiner_tmpl
This commit removes some extra empty lines from the generated code by
appending
-to the end of the template definitions. Also, it refactorsone conditional into an assignment.
Release note: None
colexec: fix a bug in hash table when null equality is allowed
Previously we incorrectly were handling the case of allowed null
equality in the hash table (which is used by the hash grouper and
unordered distinct) - we were resetting groupID of the tuple on the
probe side of that tuple has NULL value in the equality column whereas
the build tuple has a non-NULL value. This could result in incorrectly
populated
samearray and is now fixed.Release note: None
colexec: add unordered distinct
This commit adds an unordered distinct operator. The operator simply
builds a hashTable on the first call to Next() on the whole input, then
iterates over all of the tuples to check whether the tuple is the "head"
of a linked list that contain all of the tuples that are equal on
distinct columns. Only the "head" is included into the big selection
vector. Once the big selection vector is populated, the operator
proceeds to returning the batches according to a chunk of the selection
vector.
This doesn't take into account whether the input is partially ordered,
and this item is left as a follow-up work.
Fixes: #39240.
Release note (sql change): vectorized execution engine now supports
DISTINCT on unordered input.
colexec: fix hash grouper
Previously, hash grouper could hit an internal error of index outside of
range when it was looking for the "head" of a linked list. Now this is
fixed by refactoring the code in question. I think the code is now more
comprehensible.
There is no release note since hash grouper so far has been used only
with
experimental_on.Release note: None
distsql: enhance testing columnar aggregator against processor
This commit adds an ability to insert NULL values into grouping columns
and increases the number of grouping columns tested (previously it was
hard-coded as one). ANY_NOT_NULL aggregate is now skipped since it
returns non-deterministic output.
This change required modifications to the test harness to allow the
results of aggregation to deviate slightly when operating on float
values because direct string matching will not work in some cases.
Also, this commit extracts out arguments to the test harness into
a separate struct.
Release note: None