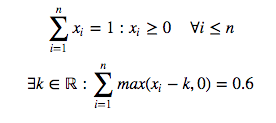I have created a variable scope in one part of my graph, and later in another part of the graph I want to add OPs to an existing scope. That equates to this distilled example:
import tensorflow as tf
with tf.variable_scope('myscope'):
tf.Variable(1.0, name='var1')
with tf.variable_scope('myscope', reuse=True):
tf.Variable(2.0, name='var2')
print([n.name for n in tf.get_default_graph().as_graph_def().node])
Which yields:
['myscope/var1/initial_value',
'myscope/var1',
'myscope/var1/Assign',
'myscope/var1/read',
'myscope_1/var2/initial_value',
'myscope_1/var2',
'myscope_1/var2/Assign',
'myscope_1/var2/read']
My desired result is:
['myscope/var1/initial_value',
'myscope/var1',
'myscope/var1/Assign',
'myscope/var1/read',
'myscope/var2/initial_value',
'myscope/var2',
'myscope/var2/Assign',
'myscope/var2/read']
I saw this question which didn’t seem to have an answer that addressed the question directly: TensorFlow, how to reuse a variable scope name
Solution:
Here is one straightforward way to do this using as with somename in a context manager. Using this somename.original_name_scope property, you can retrieve that scope and then add more variables to it. Below is an illustration:
In [6]: with tf.variable_scope('myscope') as ms1:
...: tf.Variable(1.0, name='var1')
...:
...: with tf.variable_scope(ms1.original_name_scope) as ms2:
...: tf.Variable(2.0, name='var2')
...:
...: print([n.name for n in tf.get_default_graph().as_graph_def().node])
...:
['myscope/var1/initial_value',
'myscope/var1',
'myscope/var1/Assign',
'myscope/var1/read',
'myscope/var2/initial_value',
'myscope/var2',
'myscope/var2/Assign',
'myscope/var2/read']
Remark
Please also note that setting reuse=True is optional; That is, even if you pass reuse=True, you’d still get the same result.
Another way (thanks to OP himself!) is to just add / at the end of the variable scope when reusing it as in the following example:
In [13]: with tf.variable_scope('myscope'):
...: tf.Variable(1.0, name='var1')
...:
...: # reuse variable scope by appending `/` to the target variable scope
...: with tf.variable_scope('myscope/', reuse=True):
...: tf.Variable(2.0, name='var2')
...:
...: print([n.name for n in tf.get_default_graph().as_graph_def().node])
...:
['myscope/var1/initial_value',
'myscope/var1',
'myscope/var1/Assign',
'myscope/var1/read',
'myscope/var2/initial_value',
'myscope/var2',
'myscope/var2/Assign',
'myscope/var2/read']
Remark
Also, please note that setting reuse=True is again optional; That is, even if you pass reuse=True, you’d still get the same result.