We have a new position paper on "inference time compute" and what we have been working on in the last few months! We present some theory on why it is necessary, how does it work, why we need it and what does it mean for "super" intelligence.
We have a new preprint out - your language model is not a reward, it’s a Q function!
1. The likelihood of the preferred answer must go down - it’s a policy divergence
2. MCTS guided decoding on language is equivalent to likelihood search on DPO
3. DPO learns credit assignment
Super excited to announce what we have been working on in the last six months - Agent Q is out now! This is a framework for self-supervised agent reasoning and search that can self-correct and autonomously improve by self-play and RL on real tasks on the real internet! 👇
The most surprising thing working on this was that RL with LoRA completely matches full training and develops the same extended reasoning patterns. I think this is a great sign for custom agent training.
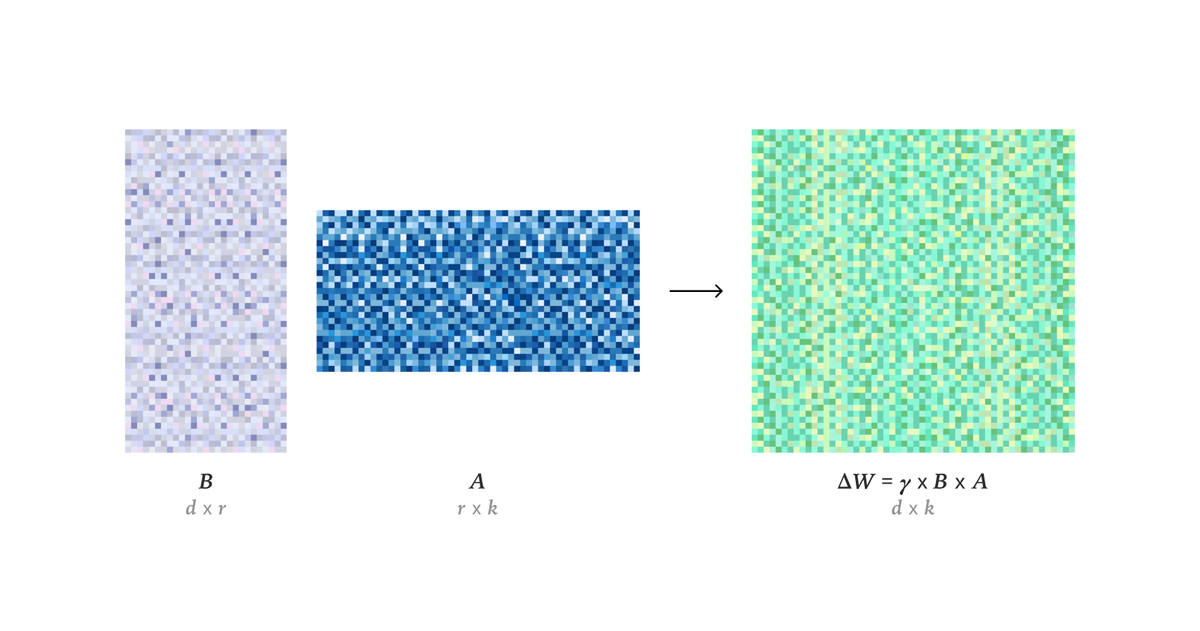
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
Excited to announce DPO has gone multi-modal! New paper out on RLHF for text-to-image diffusion models! We obtain large-scale state of the art results with 70% win rates against Stable Diffusion XL on human evals! Deep dive below 🧵
My Bet: Strawberry is algorithm distillation/procedural cloning. Everyone right now is coming up with ways to distill System 2 into System 1, but that will always be limited. We need to train the model to run the algorithms, not just outputs (and post-train with RL of course).
I saw this challenge aimoprize.com to develop an AI that can win a gold medal at the IMO. I competed at that level a couple of times (only silver medals though) and have been working on RL and LLMs for a bit. Here is my thoughts on what the challenges are:
1/N
Not to mention that most students don’t even have access to that cluster. I don’t have access to any A100s myself. It is becoming increasingly hard to even do research and that is Stanford, other places have it even worse.
Excited to announce our latest work on generative reward models that unify RLHF and RLAIF approaches! We begin with a standard LLM-as-a-judge RLAIF framework and use further RL tuning to align the judge model's evaluations with the preference dataset.
I actually believe Tinker could be the most advanced ML system in the world. It optimizes everything from the kernel level to a distributed system that can process millions of simultaneous requests with near 100% reliability and insane throughput efficiency.
So excited about this! Tinker provides a simple+powerful interface for postraining/RL research. It also manages all the infrastructure so that users can focus on data and environments.
Hidden behind that simple interface is a ton of interesting and complex ML systems challenges!
My Bet: Strawberry is algorithm distillation/procedural cloning. Everyone right now is coming up with ways to distill System 2 into System 1, but that will always be limited. We need to train the model to run the algorithms, not just outputs (and post-train with RL of course).
Very excited to share what I have been working on with a great team of people at @thinkymachines. Tinker is a whole new way to train and customize models all the way up to frontier scale. Most importantly, it allows everyone to use their own code, data, tools and environments,
Introducing Tinker: a flexible API for fine-tuning language models.
Write training loops in Python on your laptop; we'll run them on distributed GPUs.
Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
This is a really cool project where we trained a multi-agent system of 3 LLMs to do cooperative problem-solving end-to-end with reinforcement learning! MARL holds a lot of promise to teach models to be more cooperative with real collaborators! Check out @sumeetrm's thread bellow!
Introducing MALT: Improving Reasoning with Multi-Agent LLM Training🫡
We present a new multi-agent post-training method that uses credit assigned synthetic data to improve the reasoning capabilities and self-correction rates of a generator, critic, and refinement model working