"neural networks need to be adversarially robust like the human visual cortex. like you shouldn't be able to change a few pixels and completely change the semantic meaning of an image"
the human visual cortex:
we have a material that's
1. chemically inert (ie safe for everything including food)
2. made of the crust's most abundant element
3. easily created with stone age tech
4. harder than steel
5. transparent
also if it gets really hot it becomes a semiconductor
praise gaia
watching a new ML grad student say that their research direction is using neuroscience as inspiration to make new architectures (can't interfere, it's a canon event)
first chess tournament in 17 years
i was so scared of getting demolished by a 2nd grader but joke's on me
my elo was literally not high enough to get paired with any children
"linear algebra has no surprises, if it seems true it probably is"
you underestimate my dumb bitch energy. also if you weren't surprised by the wigner semicircle law kindly go fuck yourself and then give me your geometric intuition 🙏
[1/9] We created a performant Lipschitz transformer by spectrally regulating the weights—without using activation stability tricks: no layer norm, QK norm, or logit softcapping. We think this may address a “root cause” of unstable training.
nn layers align their singular vectors
each matrix syncs to its neighbor, its rotation neatly clicking into the basis directions of the next rotation. like two gears precision-machined to be partners
LLMs are swiss watches, ticking in a billion-dimensional pocket universe
overheard in roonchat: imma outsource flirting on dating apps to GPT-3
bro GPT-3 is curve-fitted over all reddit posts with >3 upvotes. you're handing your sex life to the perfect robo-redditor; i wouldn't even hand it a grocery list
DPO's method of removing RL from RLHF is so based
> previously "forced" to sample trajectories with RL bc direct optimization would require an intractable partition fn Z(x)
> observe that the bradley-terry model has a few extra degrees of freedom
> simply set Z(x)=1
zoomers were born into a post-SVM world. "kernel trick" means nothing to someone who has never known ML without self-supervised representations. the kids only respect scale
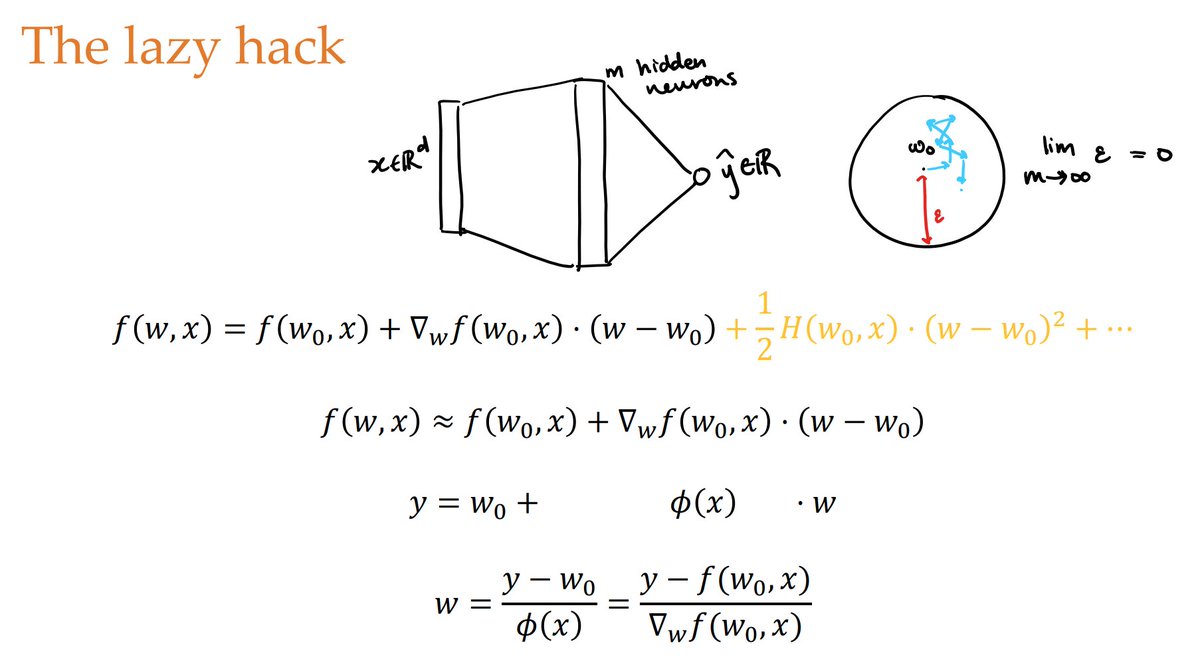
therefore i propose to rename "neural tangent kernel" to "infinite-width neural net (Taylor's version)"