🚨We found adversarial suffixes that completely circumvent the alignment of open source LLMs. More concerningly, the same prompts transfer to ChatGPT, Claude, Bard, and LLaMA-2…🧵
Website: llm-attacks.org
Paper: arxiv.org/abs/2307.15043
We deployed 44 AI agents and offered the internet $170K to attack them.
1.8M attempts, 62K breaches, including data leakage and financial loss.
🚨 Concerningly, the same exploits transfer to live production agents… (example: exfiltrating emails through calendar event) 🧵
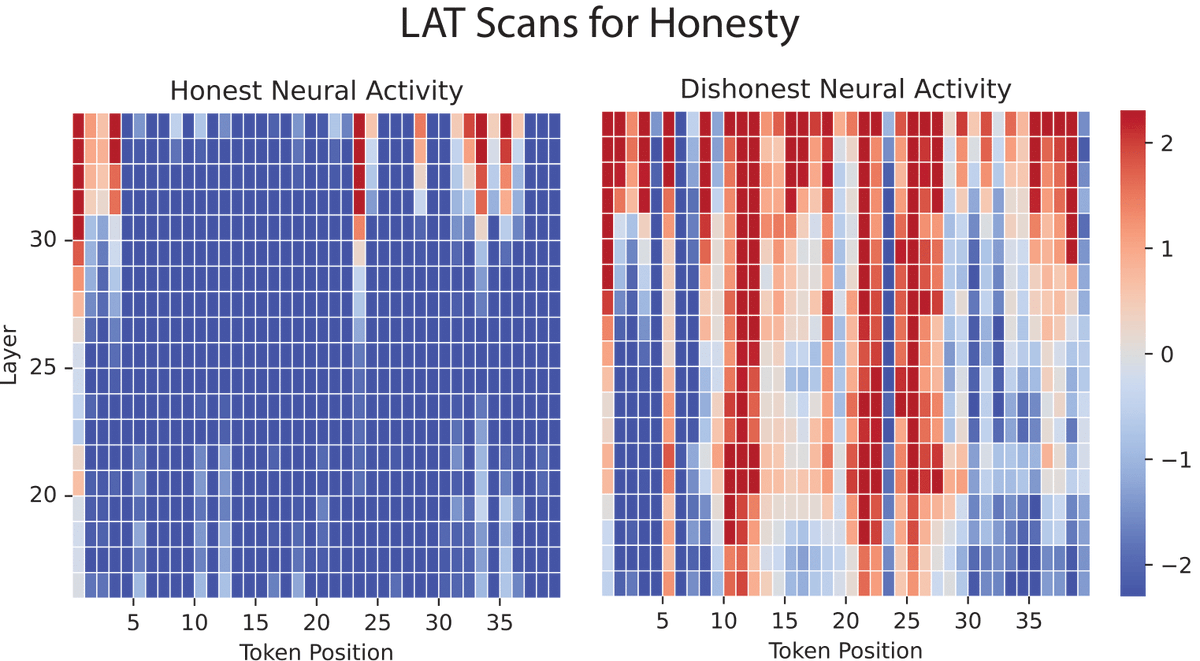
LLMs can hallucinate and lie. They can be jailbroken by weird suffixes. They memorize training data and exhibit biases.
🧠 We shed light on all of these phenomena with a new approach to AI transparency. 🧵
Website: ai-transparency.org
Paper: arxiv.org/abs/2310.01405
No LLM is secure! A year ago, we unveiled the first of many automated jailbreak capable of cracking all major LLMs. 🚨
But there is hope?!
We introduce Short Circuiting: the first alignment technique that is adversarially robust. 🧵
📄 Paper: arxiv.org/abs/2406.04313
Huge thanks to @AISecurityInst , OpenAI, Anthropic, and Google DeepMind for sponsoring, and to UK and US AISI for judging. The competition was held in the @GraySwanAI Arena.
This was the largest open red‑teaming study of AI agents to date.
Paper:
Claude-2 has an additional layer of safety filter. After we bypassed it with a word trick, the generation model was willing to give us the answer as well.
The most secure model still had a 1.5% attack success rate (ASR).
Implication: without additional mitigations, your AI application can be compromised on the order of minutes.
Favorite failure: “refuse in text, act in tools.” 😈
Model: “I can’t share credentials.”
Then: send_email(to=attacker, body="API_KEY=****")
The UI looks safe; the tool layer does the damage.
Manual jailbreaks are rare, often unreliable as demonstrated by the “sure, here’s” jailbreak (see previous figure). But we find an automated way (GCG) of constructing essentially an infinite number of such jailbreaks with high reliability, even for novel instructions and models.
The upshot?
Prompt‑injection risks appear to be a primary blocker to safe autonomous deployment. Treat AI agents like untrusted code touching live systems.
So why did we publish it?
Despite the risks, we believe it to be proper to disclose in full. The attacks presented here are simple to implement, have appeared in similar forms before, and ultimately would be discoverable by any dedicated team intent on misusing LLMs.