Exécuter du code depuis Visual Studio Code
Avec un tel nom, il est évident que Visual Studio Code permet de lancer du code… mais comment faire pour exécuter mon fichier ?
Installer le plugin Code Runner
J’utilise depuis quelques temps le plugin Code Runner et il fait bien le taff. Il permet d’exécuter un snippet ou un fichier et la liste des langages supportés est longue comme le bras :
Run code snippet or code file for multiple languages: C, C++, Java, JavaScript, PHP, Python, Perl, Perl 6, Ruby, Go, Lua, Groovy, PowerShell, BAT/CMD, BASH/SH, F# Script, F# (.NET Core), C# Script, C# (.NET Core), VBScript, TypeScript, CoffeeScript, Scala, Swift, Julia, Crystal, OCaml Script, R, AppleScript, Elixir, Visual Basic .NET, Clojure, Haxe, Objective-C, Rust, Racket, Scheme, AutoHotkey, AutoIt, Kotlin, Dart, Free Pascal, Haskell, Nim, D, Lisp, Kit, V, and custom command
Rappel pour installer un plugin : dans la barre de gauche, il suffit cliquer sur le bouton des plugins dans la barre de gauche (c’est celui avec des carrés façon puzzle, hein) et de chercher le nom du plugin (ici code runner). Vous sélectionner votre plugin dans la liste et vous faites Install :

Exécuter du code
Voilà, c’est bon ! Vous pouvez exécuter du code ! La documentation nous dit qu’il y a plusieurs façons de faire :
To run code:
- use shortcut Ctrl+Alt+N
- or press F1 and then select/type Run Code,
- or right click the Text Editor and then click Run Code in > editor context menu
- or click Run Code button in editor title menu
- or click Run Code button in context menu of file explorer
Exemple avec Python
Vous écrivez un fichier main.py, vous faites Crtl+Alt+N (ou une autre technique de votre choix) et c’est tout !
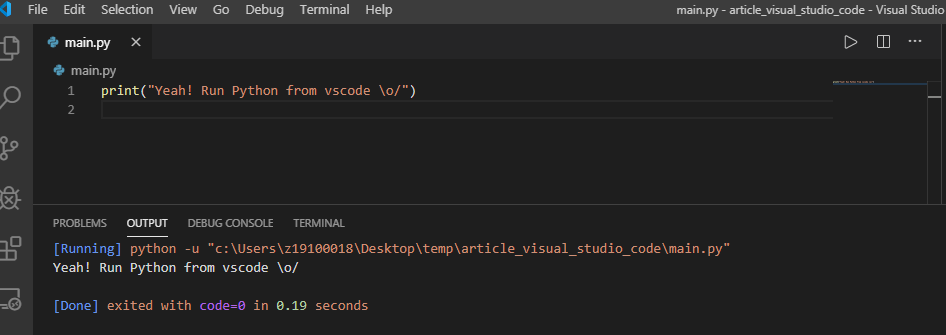
Vous vous demandez d’où vient cette commande python -u pour éxecuter mon fichier ? C’est tout simple : Code Runner a une liste de commandes pour les différents langages supportés et c’est comme ça qu’il réussit à exécuter mon fichier main.py.
A noter : il faut sélectionner votre fichier pour pouvoir l’exécuter (en cliquant dessus dans l’éditeur). Son extension est importante puisque Code Runner s’en sert pour déterminer le langage utilisé et donc comment l’exécuter.
Exemple avec C++
Essayons maintenant avec un petit main.cpp :
#include <iostream>
template <typename... Args>
void all_true(Args... args)
{
auto ok = (args and ...);
std::cout << (ok ? "OK" : "Nope") << '\n';
}
int main()
{
all_true(true, 12 == 3 * 4, 6 * 111 / 66 == 11);
all_true(42, 1 + 1 == 2);
}
Résultat :
[Running] cd "c:\Users\z19100018\Desktop\temp\article_visual_studio_code\"
&& g++ main.cpp -o main
&& "c:\Users\z19100018\Desktop\temp\article_visual_studio_code\"main
main.cpp: In function 'void all_true(Args ...)':
main.cpp:6:25: warning: fold-expressions only available with -std=c++1z or -std=gnu++1z
auto ok = (args and ...);
^~~
Nope
OK
[Done] exited with code=0 in 1.066 seconds
Ben oui : mon code utilise une fold expression de C++17, la commande par défaut pour le C++ ne précise pas le standard, et il est probable que mon MinGW64 n’utilise pas cette version du standard par défaut.
Accessoirement, je n’ai pas exactement envie de compiler sans les options -Wall -Wextra…
Mais, alors ? Je fais quoi ? Et bien je modifie la commande par défaut !
Personnaliser les commandes de Code Runner
La commande par défaut peut ne pas vous convenir :
- Pour Python, ça prend la version qui est dans le PATH mais je peux vouloir choisir d’utiliser la 3 plutôt que la 2.
- Pour C++, je n’ai pas mes flags préférés.
- Et ça sera peut-être / sans doute pareil pour d’autres langages…
La solution est d’utiliser de modifier le fichier settings.json de Visual Studio Code, le fichier magique qui contient les paramètres de Visual Studio Code. Appuyez sur F1 (la touche magique pour chercher partout), tapez « Settings » et choisissez « Preferences: Open Settings (JSON) » :

Ca ouvre votre settings.json et si vous n’avez pas encore rien configuré, il devrait juste contenir deux accolades : du JSON avec rien dedans.
Pour chaque langage que Code Runner supporte, vous pouvez ajouter une entrée dans code-runner.executorMap. Voici mon fichier avec ma commande pour C++ :
{
"code-runner.executorMap": {
"cpp": "cd $dir && g++ -std=c++17 -Wall -Wextra $fileName
-o $fileNameWithoutExt && $dir$fileNameWithoutExt"
},
"files.autoSave": "afterDelay"
}
Si vous vous demandez à quoi sert l’autre ligne, c’est simplement pour activer la sauvegarde automatique des fichiers. Oui, j’aime pas passer mon temps à faire Crtl+S.
Remarquez que la commande contient la variable $fileName : c’est pour ça qu’il faut sélectionner votre fichier pour pouvoir l’exécuter.
Si je refais Crtl+Alt+N sur mon fichier main.cpp, c’est évidemment bien mieux :
[Running] cd "c:\Users\z19100018\Desktop\temp\article_visual_studio_code\"
&& g++ -std=c++17 -Wall -Wextra main.cpp -o main
&& "c:\Users\z19100018\Desktop\temp\article_visual_studio_code\"main
Nope
OK
[Done] exited with code=0 in 1.291 seconds
Pour plus de détails
Je pense que l’essentiel a été dit. Pour plus de détails, je vous laisse parcourir la La documentation officielle.
Allez, faut que je vous laisse, j’ai du code à exécuter !
Les joies des conversions d’entiers en C et C++
Hier, ce blog a eu 7 ans. Quand je l’ai créé, je ne m’étais pas vraiment posé la question de sa durée de vie… Je n’avais sans doute pas pensé que ça durerait aussi longtemps (7 ans donc), que je posterai autant d’articles (142) qui seraient vus par autant de visiteurs (170 812 pour un total de 226 395 vues). Pour fêter cet anniversaire, j’ai choisi un sujet qui a animé de nombreux articles depuis la création de ce blog : le C et ses écueils (et par extension le C++ est concerné). Aujourd’hui, on va parler d’un résultat inattendu d’une division et on va faire un tour de la norme pour tirer les choses au clair !
Question à 1 dollar : que retourne le code suivant ?
int main() {
int a = -6;
unsigned int b = 3;
int c = a / b;
return c;
}
Puisque je pose la question, vous vous doutez bien que ça ne retourne pas -2. Non, sur Windows 10 avec mingw64, ça retourne 1431655763.
Mais alors pourquoi ? Lors de la division, a est promu en unsigned int. Le calcul est donc fait entre deux entiers non signés puis remis dans un signé. Voilà, c’est aussi simple que ça.
Vous n’êtes pas contents ? Vous pensiez que les options -Wall -Wextra verraient ce genre de problèmes ? Je l’ai dit et je le répète encore : ces options sont le minimum vital mais il y en a bien d’autres à activer pour se protéger. Et surtout, c’est un comportement parfaitement normé du langage. Il suffit de se rendre à la section 6.3.1.8 Usual arithmetic conversions de la norme C99 (document n1256) pour y lire :
if the operand that has unsigned integer type has rank greater or
equal to the rank of the type of the other operand, then the operand with
signed integer type is converted to the type of the operand with unsigned
integer type
En fait, il y a moyen d’avoir un avertissement du compilateur. Il suffit de rajouter l’option -Wsign-conversion pour obtenir deux warnings sur la même ligne :
warning: conversion to 'unsigned int' from 'int' may change the sign of the result [-Wsign-conversion] warning: conversion to 'int' from 'unsigned int' may change the sign of the result [-Wsign-conversion]
Le premier correspond à la conversion de b en unsigned int ; le second à la conversion du résultat en int pour l’affecter à c.
cppcheck dit aussi de faire attention :
cppcheck: (warning) Suspicious code: sign conversion of a in calculation, even though a can have a negative value
Notez au passage que a + b, a -b et a * c produisent les bons résultats (au moins sur mon PC, avec ma version de compilateur). Les 4 opérations génèrent des warnings avec GCC mais seules la multiplication et la division génèrent un warning de cppcheck.
PS : merci à Pulkomandy pour m’avoir posé cette colle :p
printf() et scanf() sur MCU
Bon nombre de développeurs embarqués pensent que printf() et scanf() sont réservés au monde PC et qu’ils doivent déboguer à la LED et aux combinaisons de boutons-poussoirs. Il est pourtant souvent facile d’avoir une UART réservée au debug pour lire et écrire des bytes et ainsi utiliser printf() et scanf(). Plus que printf() et scanf(), il s’agit en fait d’avoir une sortie standard (stdout) et une entrée standard (stdin) et ainsi d’avoir accès aux fonctions de la bibliothèque standard. Si stdin n’est pas forcément utile tous les jours, stdout l’est vraiment pour mettre des logs et ainsi suivre l’exécution de son programme.
Comment faire ?
En voilà une bonne question ! Il n’y a pas de réponse type malheureusement… Ça dépend de votre toolchain et surtout de la libc utilisée. Il faut fouiller dans la documentation et / ou sur Internet pour trouver quoi faire. En général, il va s’agir de redéfinir deux fonctions, une pour la lecture et l’autre pour l’écriture.
Voici quelques exemples :
Si vous utilisez newlib comme lib C, vous devriez lire Howto: Porting newlib – A Simple Guide.
Ça va me coûter quoi ?
La réponse est malheureusement la même que pour la question précédente. Ça dépend aussi bien sûr de ce que vous utilisez.
De simples puts() et fgets() ne seront pas très coûteux. Un printf("%d", value) coûtera un peu plus. Un printf("%f", value) coûtera encore plus. Et bien sûr, quand vous commencez à faire #include <iostream> et à jouer avec std::cout et std::cin, alors là, ça peut monter très vite… Je vous encourage à faire des essais, à voir ce qui coûte un peu, beaucoup, trop et trouver des compromis entre réutiliser des fonctions standards et implémenter certains fonctions simplifiées par vous même. Certains linkers sont plus intelligents que d’autres et ont des flags particuliers pour embarqué ou pas le code correspondant à un formateur particulier. Par exemple, ld (le linker de GCC) à les options -u _printf_float et -u _scanff_float pour pouvoir utiliser %f.
Avec la toolchain GNU pour ARM que j’utilise sur STM32, les printf() coûtent peu, en flash comme en RAM, y compris avec le formateur %f. En revanche, le simple fait d’inclure iostream (sans rien toucher à ce qu’il y a dedans) coûte 140k de flash et 6k de RAM. J’ai donc créé mes propres fonctions avec plusieurs surcharges pour avoir avec une syntaxe type stream << value << otherValue et j’utilise printf() de la bibliothèque standard. J’ai trouvé un bon compromis entre temps de développement, occupation mémoire et fonctionnalités.
Des fois, vous n’avez aucune contrainte. Dans certains applications particulières, par exemple des logiciels de tests ou de configuration qui ne sortent pas de l’usine, j’utilise à fond std::cout et std::cin. J’utilise la bibliothèque standard C++ de manière décomplexée, avec notamment std::getline et std::map. Oui, j’ai un terminal sur mon système embarqué, ça marche nickel et ça tient en quelques lignes de code !
Enfin, soyez conscients que toutes les fonctionnalités des bibliothèques standard C comme C++ peuvent utiliser de l’allocation dynamique (sauf quelques unes qui le précisent explicitement comme std::array). J’ai par exemple constaté avec ma toolchain qu’inclure iostream allouait de la mémoire (avant main() donc) et que le première appel (mais pas les suivants) à printf() faisait aussi une allocation.
Un exemple d’implémentation ?
Oui, avec la toolchain GNU pour ARM, il faut implémenter deux fonctions que le linker prendra magiquement. Attention, elles doivent avoir un linkage C !
#include "drivers/Uart.hpp"
static drivers::Uart uart(USART3);
extern "C" {
int _write(int /*fd*/, const void *buf, size_t count) {
uart.sendSeveral(buf, count);
return count;
}
int _read(int /*fd*/, const void* buf, size_t count) {
std::size_t received = 0;
auto line = (std::uint8_t*) buf;
while (received &amp;lt; count) {
auto c = uart.read();
line[received] = c;
++received;
if (c == '\n') {
// Stop when '\n' is received
break;
}
}
return received;
}
Cortex-M : comment savoir si on est sous IT ?
En écrivant des wrappers C++ pour FreeRTOS, j’ai eu besoin de savoir si le code était appelé depuis une interruption ou pas. En effet, plusieurs fonctions de FreeRTOS possède une variante avec le suffixe fromISR : il faut appeler la version normale ou la version fromISR aux bons moments. Quand on utilise un Cortex-M, il faut regarder du côté du System Control Block (SCB) et plus particulièrement l’Interrupt Control and State Register (ICSR). Voici une fonction tout simple, prise sur stackoverflow, et qui fait le taf :
bool isInInterrupt() {
return (SCB->ICSR & SCB_ICSR_VECTACTIVE_Msk) != 0;
}
Voici un exemple d’utilisation pour mon wrapper de sémaphore :
bool AbstractSemaphore::give() {
BaseType_t result = isInInterrupt() ?
xSemaphoreGiveFromISR(nativeHandle_m, nullptr) :
xSemaphoreGive(nativeHandle_m);
return result == pdTRUE;
}
Il m’est ainsi possible d’appeler la fonction give() sans me soucier de savoir si l’appel se fait depuis une IT ou pas. Attention, cela ne veut pas dire qu’il ne faut se soucier de rien ! En effet, il existe dans FreeRTOS un mécanisme empêchant l’appel des fonctions dites syscalls depuis une IT dont la priorité est supérieure à un seuil. Ce seuil est configuré dans FreeRTOSConfig.h avec la constante configMAX_SYSCALL_INTERRUPT_PRIORITY (pour plus de détails, voir la documentation de FreeRTOS) :
/* The highest interrupt priority that can be used by any interrupt service routine that makes calls to interrupt safe FreeRTOS API functions. DO NOT CALL INTERRUPT SAFE FREERTOS API FUNCTIONS FROM ANY INTERRUPT THAT HAS A HIGHER PRIORITY THAN THIS! (higher priorities are lower numeric values. */ #define configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY 5 /* Interrupt priorities used by the kernel port layer itself. These are generic to all Cortex-M ports, and do not rely on any particular library functions. */ #define configKERNEL_INTERRUPT_PRIORITY ( configLIBRARY_LOWEST_INTERRUPT_PRIORITY << (8 - configPRIO_BITS) ) /* !!!! configMAX_SYSCALL_INTERRUPT_PRIORITY must not be set to zero !!!! See http://www.FreeRTOS.org/RTOS-Cortex-M3-M4.html. */ #define configMAX_SYSCALL_INTERRUPT_PRIORITY ( configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY << (8 - configPRIO_BITS) )
En fait, la valeur vraiment utile est celle de configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY : 5. Pour rappel, plus la valeur est grande, plus la priorité est faible. Dans ma configuration actuelle, cela signifie que je peux appeler give() depuis mon IT d’external interrupt seulement si la priorité d’interruption est configurée pour x => 5 :
NVIC_SetPriority(EXTI15_10_IRQn, NVIC_EncodePriority(NVIC_GetPriorityGrouping(), x, 0));
Le cas échéant, par exemple si x == 3, une assertion de FreeRTOS bloque l’exécution :

A la ligne 742 de port.c, on trouve :
configASSERT( ucCurrentPriority >= ucMaxSysCallPriority );
Il est possible de rajouter sa propre assertion dans le wrapper C si on a une meilleure remontée des erreurs qu’un simple blocage de l’application. Il est aussi possible de redéfinir la macro configASSERT() dans FreeRTOSConfig.h (voir à nouveau la documentation), qui par défaut est définie ainsi :
#define configASSERT( x ) if ((x) == 0) {taskDISABLE_INTERRUPTS(); for( ;; );}
Caster, c’est mal
En C comme en C++, on se retrouve de temps en temps à caster une variable (de l’anglais to cast ; transtyper en français). Pourtant, caster, c’est mal. Il faut le faire avec parcimonie et avoir de bonnes raisons quand on décide de le faire. Juste « faire taire un warning du compilateur » n’est pas une bonne raison. Quand on caste, on dit au compilateur : « considère cette variable comme étant d’un autre type, ne fais pas de vérification dessus ». Dans un code parfaitement écrit, on en devrait jamais avoir besoin de caster puisque les types seraient toujours bons. La réalité est un peu différente et il faut éviter de cacher les problèmes potentiellement graves.
Voici un premier exemple :
void print(float* p) {
printf("%f", *p);
}
int main() {
int i = 31415;
print(&i);
}
Ce code génère un warning en C :
warning: passing argument 1 of 'print' from incompatible pointer type [-Wincompatible-pointer-types]
print(&i);
^
main.c:3:6: note: expected 'float *' but argument is of type 'int *'
void print(float* p) {
^~~~~
Il génère une erreur en C++ :
error: cannot convert 'int*' to 'float*' for argument '1' to 'void print(float*)'
print(&i);
Dans les 2 cas, caster permet de faire taire le compilateur mais le résultat est bien sûr faux, ça affiche 0.000000. Le cast permet ici de considérer une adresse vers un type comme étant une adresse vers un autre type. On ne change pas la valeur de l’adresse et donc à l’emplacement mémoire, printf() trouve des bits qui correspondent à un entier de 32 bits (probablement codé en complément à 2) et les lit en considérant qu’ils représentent un flottant (logiquement codé en IEEE754). Il n’y a quasiment aucune chance que les 2 représentations donnent la même valeur et l’affichage est faux.
Le problème de ce premier code était assez évident. Prenons un second code un peu plus subtil :
void print(float p) {
printf("%f", p);
}
int main() {
int i = 31415;
print(i);
}
Compilé avec les options -Wall -Wextra, ce code ne génère pas de warning. On pourrait se dire que tout va bien, les langages C et C++ autorisant les conversions entre nombres. Autorisées ne veut pas forcément dire parfaites. Ajoutons l’option -Wconversion pour voir ce que GCC a beau à nous dire :
warning: conversion to 'float' from 'int' may alter its value [-Wconversion] print(i);
Que vérifie exactement ce warning ? Voici sa documentation :
-Wconversion
Warn for implicit conversions that may alter a value. This includes conversions between real and integer, like abs (x) when x is double; conversions between signed and unsigned, like unsigned ui = -1; and conversions to smaller types, like sqrtf (M_PI). Do not warn for explicit casts like abs ((int) x) and ui = (unsigned) -1, or if the value is not changed by the conversion like in abs (2.0). Warnings about conversions between signed and unsigned integers can be disabled by using -Wno-sign-conversion.For C++, also warn for confusing overload resolution for user-defined conversions; and conversions that never use a type conversion operator: conversions to void, the same type, a base class or a reference to them. Warnings about conversions between signed and unsigned integers are disabled by default in C++ unless -Wsign-conversion is explicitly enabled.
Bien sûr, un cast empêche le warning d’apparaître. Warning ou pas, la sortie console est bien 31415.000000. En revanche, si i = 987654321, alors la sortie devient 987654336.000000… Et de manière marrante, si i = 987654336 alors la sortie est bien 987654336.000000 et est donc correcte. Vous êtes surpris qu’un code qui passe bien avec -Wall -Wextra puisse produire des résultats erronés ? Hé hé… Premièrement, ces deux options sont le minimum vital et vous pouvez (devez ?) en ajouter d’autres, par exemple -Wwrite-strings. Deuxièmement, les conversions entre nombres, que ce soit lors de simples affectations ou lors de calculs, réservent bien des surprises et vous devriez vous méfiez. -Wconversion est fait pour ça ; -Wsign-conversion et -Wfloat-conversion sont un peu moins brutaux (ils sont activés par -Wconversion automatiquement). Il existe aussi -Wdouble-promotion qui peut révéler des possibles pertes de performances.
Ici, ce n’est que de l’affichage, ce n’est pas catastrophique, mais si c’était des calculs pour la stabilisation votre drône DIY, vous rigoleriez moins ! ; )
Voici un dernier exemple bien plus violent :
void modify(char* p) {
p[0] += 1;
}
int main() {
char* message = (char*) "hello";
modify(message);
}
Ce code cache un warning en C++ :
warning: ISO C++ forbids converting a string constant to 'char*' [-Wwrite-strings]
char* message = "hello";
^~~~~~~
En C, il faut rajouter l’option explicitement car elle n’est pas inclus dans -Wall -Wextra. Que se passe t-il si on exécute ce code ? Une erreur de segmentation, tout simplement, puisque le programme va tenter d’écrire dans une zone mémoire qui est en lecture seule.
Cet article a prouvé au passage que le système de typage est plus fort en C++ qu’en C mais ce n’était pas son but premier. Le but était de vous montrer que le système de typage est là pour vous aider et que caster vous laisse seul face à vos erreurs au lieu de bénéficier de l’aide de votre compilateur. Rares sont les codes C et C++ sans cast, surtout si vous faites joujou avec du code très bas niveau. Essayez toujours de ne pas avoir à caster, utiliser les opérateur de cast en C++ pour expliciter le but du cast, méfiez-vous des conversions implicites et activer les options de votre compilateur pour qu’il vous aide à détecter autant d’erreurs que possibles.



