[EventEngine] Implement work-stealing in the EventEngine ThreadPool#32869
[EventEngine] Implement work-stealing in the EventEngine ThreadPool#32869drfloob merged 55 commits intogrpc:masterfrom
Conversation
…c#32935) Fix: grpc#18075 From comments in grpc#18075, `CPython` reinitialize the `GIL` after `pthread_atfork` child handler, thus we shouldn't use any `GIL` related functions in child handler which is what we're currently doing, this PR uses `os.register_at_fork` to replace `pthread_atfork` to prevent any undesired bevahior. This also seems to fixes a thread hanging issue cased by changes in core: grpc#32869 ### Testing: * Passed existing fork tests. (Note that due to some issues in `Bazel`, this change was not verified by `Bazel runs_per_test`). * Tested by patch the core PR, was able to fix Python fork tests: grpc#32933
 Vignesh2208
left a comment
Vignesh2208
left a comment
There was a problem hiding this comment.
Hi AJ, reviewed the core logic and left a few suggestions. I haven't reviewed the tests yet.
| PosixEventEngine::PosixEventEngine() | ||
| : connection_shards_(std::max(2 * gpr_cpu_num_cores(), 1u)), | ||
| executor_(std::make_shared<ThreadPool>()), | ||
| executor_(MakeThreadPool(grpc_core::Clamp(gpr_cpu_num_cores(), 2u, 16u))), |
There was a problem hiding this comment.
I think the max was 32u in the original threadpool. Maybe we retain that here too and everywhere else ?
There was a problem hiding this comment.
Two primary reasons why I changed it:
-
We've had multiple complaints about an excessive number of threads for idle gRPC processes. For complete control, users can implement their own EventEngine. However using the code in this PR, if 32 threads are needed then they will be spun up eventually (a ~25s warmup period). If you'll note the benchmark results, even 8 threads here outperforms the previous implementation with 32 threads.
-
The auto-scaling mechanism here is nascent. I have one concrete idea for improved auto-scaling, but with a set of target platforms to test on, we can benchmark various auto-scalers. Getting that set of platforms is tricky in OSS though.
| EventEngine::Closure* WorkStealingThreadPool::TheftRegistry::StealOne() { | ||
| grpc_core::MutexLock lock(&mu_); | ||
| EventEngine::Closure* closure; | ||
| for (auto* queue : queues_) { |
There was a problem hiding this comment.
One potential future optimization here could be that if we have a data structure that returns the queue with the highest backlog (in-terms of queue length), it might be preferable to steal from that queue first.
It can even be coarse grained: queues can be put into 3 buckets: SMALL, MEDIUM, LARGE depending on their queue length and while stealing, we can iterate over large queues first before moving on to medium and small sized queues.
There was a problem hiding this comment.
The bucketing idea is interesting. We could also institute queue priorities, I've seen some good results there. I just wonder if the overhead of queue juggling would negate the benefits of optimizing for queue time.
One potential future optimization here could be that if we have a data structure that returns the queue with the highest backlog (in-terms of queue length), it might be preferable to steal from that queue first.
Maybe so. In my chats with @soheilhy, optimizing for queue time was not terribly fruitful in their experiments. Further, this is pop-most-recent because we have a high performance queue implementation that avoids mutexes for LIFO operations. It has some very rare atomic flake issues, so I planned to land that as a subsequent improvement.
But these are all things we can experiment with if the performance difference is meaningful.
| thread_running_.store(true); | ||
| while (true) { | ||
| absl::SleepFor(absl::Milliseconds( | ||
| (backoff_.NextAttemptTime() - grpc_core::Timestamp::Now()).millis())); |
There was a problem hiding this comment.
Why do we backoff exponentially here instead of having a fixed sleep duration ?
There was a problem hiding this comment.
Benchmarks and efficiency :-)
If the pool is highly active, we want a vigilant lifeguard because it will wake idle workers faster than the workers will wake themselves. If gRPC is idle, having the lifeguard wake up every 50 millis is needlessly expensive.
There was a problem hiding this comment.
Doesn't this mean that through line 267, the backoff timer keeps multiplying even for the case where there is some idle thread AND work to be done (i.e work queue is not empty) ?
Shouldn't the backoff timer multiply only for the case where there are idle threads but no work needs to be done (i.e the pool is empty) ?
There was a problem hiding this comment.
Indeed, good catch. Fixed.
| state.counters["pop_rate"] = benchmark::Counter( | ||
| element_count * state.iterations(), benchmark::Counter::kIsRate); | ||
| state.counters["pop_attempts"] = pop_attempts; | ||
| state.counters["hit_rate"] = |
There was a problem hiding this comment.
Can you add a comment on what the hit_rate is measuring ?
| } | ||
|
|
||
| TYPED_TEST(ThreadPoolTest, ScalesWhenBackloggedFromSingleThreadLocalQueue) { | ||
| int pool_thread_count = 8; |
There was a problem hiding this comment.
Is there an upper limit on the number of threads spawned by the thread pool ? If not, can you create some k* pool_thread_count callbacks in line 161 and line 187 to verify the lifeguard is able to create more and more threads as necessary ?
There was a problem hiding this comment.
There is no upper limit. As is, this test ensures that scaling happens, which is essential. I'm not sure if we can safely specify a minimum scale amount to assert for all implementations. Do you think some N threads would make this a better test?
The biggest issue with "more and more (N) threads" is that the pool implementation creates at most 1 thread per second, so the test could take a while depending on N.
| void ScheduleSelf(ThreadPool* p) { | ||
| p->Run([p] { ScheduleSelf(p); }); | ||
| TYPED_TEST(ThreadPoolTest, ForkStressTest) { | ||
| // Runs a large number of closures and multiple simulated fork events, |
There was a problem hiding this comment.
Can you add more comments for this test ? Is it testing that a Fork operation is not blocked indefinitely ?
Vignesh2208
left a comment
There was a problem hiding this comment.
Mostly looks good. Left a few clarifications.
Thanks Vignesh! I've updated the PR and responded to all comments. |
|
A test cherrypick was clean, no need for it. Thanks for the review! |
) Fix: #18075 From comments in #18075, `CPython` reinitialize the `GIL` after `pthread_atfork` child handler, thus we shouldn't use any `GIL` related functions in child handler which is what we're currently doing, this PR uses `os.register_at_fork` to replace `pthread_atfork` to prevent any undesired bevahior. This also seems to fixes a thread hanging issue cased by changes in core: #32869 ### Testing: * Passed existing fork tests. (Note that due to some issues in `Bazel`, this change was not verified by `Bazel runs_per_test`). * Tested by patch the core PR, was able to fix Python fork tests: #32933
…32869) This PR implements a work-stealing thread pool for use inside EventEngine implementations. Because of historical risks here, I've guarded the new implementation behind an experiment flag: `GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the original thread pool implementation. Benchmarks look very promising: ``` bazel test \ --test_timeout=300 \ --config=opt -c opt \ --test_output=streamed \ --test_arg='--benchmark_format=csv' \ --test_arg='--benchmark_min_time=0.15' \ --test_arg='--benchmark_filter=_FanOut' \ --test_arg='--benchmark_repetitions=15' \ --test_arg='--benchmark_report_aggregates_only=true' \ test/cpp/microbenchmarks:bm_thread_pool ``` 2023-05-04: `bm_thread_pool` benchmark results on my local machine (64 core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to master: 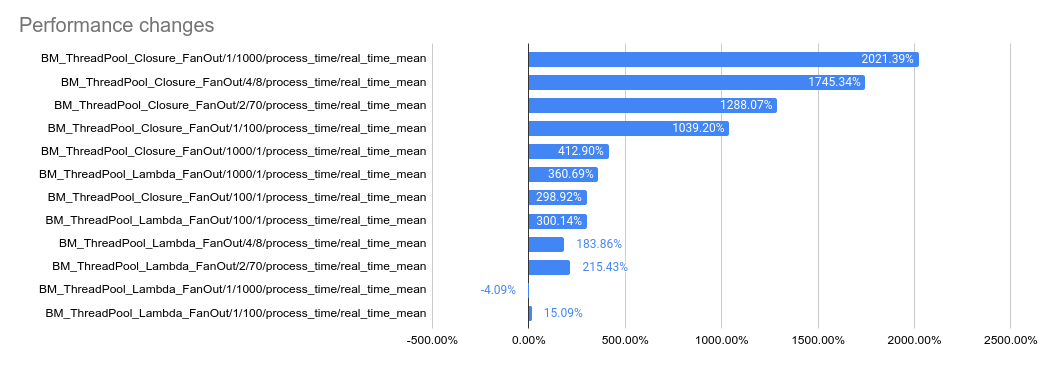 2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE environment (unsure of machine configuration, likely small), comparing this PR to master. 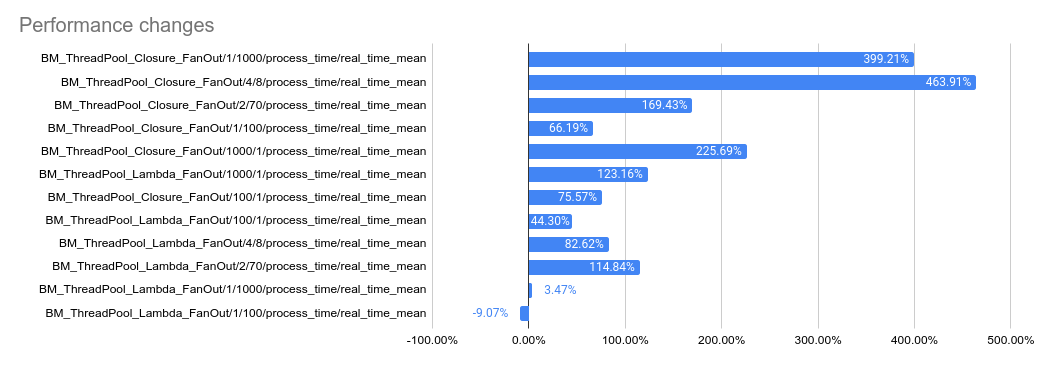 --------- Co-authored-by: drfloob <drfloob@users.noreply.github.com>
{kind=link}
{kind=link}
This PR implements a work-stealing thread pool for use inside EventEngine implementations. Because of historical risks here, I've guarded the new implementation behind an experiment flag:
GRPC_EXPERIMENTS=work_stealing. Current default behavior is the original thread pool implementation.Benchmarks look very promising:
2023-05-04:
bm_thread_poolbenchmark results on my local machine (64 core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to master:2023-05-04:
bm_thread_poolbenchmark results in the Linux RBE environment (unsure of machine configuration, likely small), comparing this PR to master.