storage: avoid blocking the command queue for scans with limits#31904
storage: avoid blocking the command queue for scans with limits#31904spencerkimball wants to merge 1 commit intocockroachdb:masterfrom
Conversation
|
This change is |
 petermattis
left a comment
petermattis
left a comment
There was a problem hiding this comment.
In the contending case, we'll perform the read twice, correct? Seems like that should usually be a win. Echoing my comment on #31663, I worry that this could be destabilizing (though the concern here is less than on #31663). Perhaps we should hold off on merging this until we've got the roachtest stability issues under control.
PS I think this fixes #9521.
Reviewable status:
complete! 0 of 0 LGTMs obtained
|
What @petermattis said. Other than worrying about the stability aspect though, I'm pretty excited about this change. (This being a perf change, it'll really need some numbers, though!). |
 bdarnell
left a comment
bdarnell
left a comment
There was a problem hiding this comment.
Yes, this fixes #9521.
Needs tests, and I'd like to see a detailed overview comment of pre-evaluation somewhere.
Release note: improved performance on workloads which mix OLAP queries
with updates.
I don't see this change as being particularly OLAP-focused. OLAP queries tend to not have limits, or to have limits after a GROUP BY or other post-processing. The LIMIT 1 seen in #9521 is definitely an OLTP use case. (The OLAP queries that run into this issue are likely indications that SQL is using a batch limit that is too small, which is something we should consider as we rethink how we handle parallelism and memory limits here)
A related topic (I thought we had an issue for this but can't find it now) is that if we acquired a rocksdb snapshot at the right time, we would not need to keep reads in the command queue while they evaluate. This might be a pessimization for the low-contention use case (especially because we have some reservations about rocksdb snapshots in general), but it might be worth considering and evaluating.
Reviewed 4 of 4 files at r1.
Reviewable status:
pkg/storage/command_queue.go, line 108 at r1 (raw file):
prereqsAndDeps []*cmd pending chan struct{} // closed when complete, or if pre-evaulating
Where exactly does pending get closed for pre-evaluating commands?
pkg/storage/command_queue_test.go, line 37 at r1 (raw file):
func add(cq *CommandQueue, from, to roachpb.Key, readOnly bool, prereqs []*cmd) *cmd { return cq.add(readOnly, false /* preEvaluate */, zeroTS, prereqs, []roachpb.Span{{Key: from, EndKey: to}})
There should be some tests in command_queue_test.go with preEvaluate set to true.
pkg/storage/replica.go, line 2430 at r1 (raw file):
// If either the command or its prereq are pre-evaluating, // resolve the prereq immediately instead of waiting. if newCmd.preEvaluate || pre.preEvaluate {
If pending is closed for preevaluating commands (as described in the comment above), we don't need the second part of this check and can fall through into the select.
pkg/storage/replica.go, line 3054 at r1 (raw file):
) (br *roachpb.BatchResponse, pErr *roachpb.Error) { br, pErr = r.tryExecuteReadOnlyBatch(ctx, ba, true /* preEvaluateOnLimits */) if pErr == nil || pErr != retryWithoutPreEvaluationError {
The pErr == nil part of this is unnecessary.
 nvb
left a comment
nvb
left a comment
There was a problem hiding this comment.
I'd like to see some tests and benchmarks demonstrating the effect of this. We'll certainly want to do something like this, but I do get the feeling that the CommandQueue is getting in your way and resulting in some artificial overhead.
A related topic (I thought we had an issue for this but can't find it now) is that if we acquired a rocksdb snapshot at the right time, we would not need to keep reads in the command queue while they evaluate. This might be a pessimization for the low-contention use case (especially because we have some reservations about rocksdb snapshots in general), but it might be worth considering and evaluating.
You might be thinking about https://forum.cockroachlabs.com/t/why-do-we-keep-read-commands-in-the-command-queue/360. There's definitely something here, and addressing it would probably simplify the code in this PR significantly. We could synchronously grab a snapshot of overlapping write spans in the CommandQueue while grabbing a RocksDB snapshot. We would then pre-evaluate and check whether our results overlap with these write spans.
We might also consider not leaving the CommandQueue while pre-evaluating. That wouldn't fit into the current code structure, but would prevent later writes from slipping in front of a pre-evaluating scan.
Reviewed 2 of 4 files at r1.
Reviewable status:
pkg/storage/replica.go, line 2430 at r1 (raw file):
Previously, bdarnell (Ben Darnell) wrote…
If
pendingis closed for preevaluating commands (as described in the comment above), we don't need the second part of this check and can fall through into theselect.
That's a nice generalization.
pkg/storage/replica.go, line 3078 at r1 (raw file):
func (r *Replica) tryExecuteReadOnlyBatch( ctx context.Context, ba roachpb.BatchRequest, preEvaluateOnLimits bool, ) (br *roachpb.BatchResponse, pErr *roachpb.Error) {
Instead of making retryWithoutPreEvaluationError an error, I'd draw a parallel with proposalRetryReason.
pkg/storage/replica.go, line 3142 at r1 (raw file):
defer func() { // If we pre-evaluated and skipped waiting in the command queue, // check for concurrent write conflicts.
This is relying on the fact that none of the read request types have the updatesTSCacheOnError flag, otherwise, a retryWithoutPreEvaluationError would still update the timestamp cache, which would be an issue. Let's make that very clear.
|
Looks like we get about 15% improvement on throughput with a modified KV which reads a value Before: After: |
|
I also ran with Before: After: |
c2d3a00 to
f8979b4
Compare
|
I'm happy to leave this PR alone. It doesn't seem crucially important; I just had an idea that seemed workable to address the issue and wanted to give it form. I'm going to leave this branch for future consideration / testing by someone who can really own this work. |
SQL has a tendancy to create scans which cover a range's entire key span, though looking only to return a finite number of results. These requests end up blocking writes in the command queue, which block other reads, causing requsets to effectively serialize. In reality, when there is a scan with a limit, the actual affected key span ends up being a small subset of the range's key span. This change creates a new "pre-evaluation" execution path for read- only requests. When pre-evaluating, the batch still interacts with the command queue, but it neither waits for pre-requisites nor causes successor, dependent write batches from waiting on it. Instead, any prereqs or dependents are tracked while the read-only batch is immediately evaluated without blocking. On successful evaluation, the actual span(s) covered and recorded in the read-only batch's `BatchResponse` are compared to the pre-requisite and dependent commands. If there is no overlap, the timestamp cache is updated and the read-only batch response returned to the caller. If there is overlap, then the read-only batch is re-executed, but with the pre-evaluation option disabled, so that it proceeds to interact with the command queue in the traditional fashion, waiting on prereqs and making dependents wait on it. Release note: improved performance on workloads which mix OLAP queries with updates.
f8979b4 to
199830b
Compare
Informs cockroachdb#4768. Informs cockroachdb#31904. This change was inspired by cockroachdb#31904 and is a progression of the thinking started in cockroachdb#4768 (comment). The change introduces `spanlatch.Manager`, which will replace the `CommandQueue` **in a future PR**. The new type isn't hooked up yet because doing so will require a lot of plumbing changes in that storage package that are best kept in a separate PR. The structure uses a new strategy that reduces lock contention, simplifies the code, avoids allocations, and makes cockroachdb#31904 easier to implement. The primary objective, reducing lock contention, is addressed by minimizing the amount of work we perform under the exclusive "sequencing" mutex while locking the structure. This is made possible by employing a copy-on-write strategy. Before this change, commands would lock the queue, create a large slice of prerequisites, insert into the queue and unlock. After the change, commands lock the manager, grab an immutable snapshot of the manager's trees in O(1) time, insert into the manager, and unlock. They can then iterate over the immutable tree snapshot outside of the lock. Effectively, this means that the work performed under lock is linear with respect to the number of spans that a command declares but NO LONGER linear with respect to the number of other commands that it will wait on. This is important because `Replica.beginCmds` repeatedly comes up as the largest source of mutex contention in our system, especially on hot ranges. The use of immutable snapshots also simplifies the code significantly. We're no longer copying our prereqs into a slice so we no longer need to carefully determine which transitive dependencies we do or don't need to wait on explicitly. This also makes lock cancellation trivial because we no longer explicitly hold on to our prereqs at all. Instead, we simply iterate through the snapshot outside of the lock. While rewriting the structure, I also spent some time optimizing its allocations. Under normal operation, acquiring a latch now incurs only a single allocation - that being for the `spanlatch.Guard`. All other allocations are avoided through object pooling where appropriate. The overhead of using a copy-on-write technique is almost entirely avoided by atomically reference counting btree nodes, which allows us to release them back into the btree node pools when they're no longer references by any btree snapshots. This means that we don't expect any allocations when inserting into the internal trees, even with the COW policy. Finally, this will make the approach taken in cockroachdb#31904 much more natural. Instead of tracking dependents and prerequisites for speculative reads and then iterating through them to find overlaps after, we can use the immutable snapshots directly! We can grab a snapshot and sequence ourselves as usual, but avoid waiting for prereqs. We then execute optimistically before finally checking whether we overlapped any of our prereqs. The great thing about this is that we already have the prereqs in an interval tree structure, so we get an efficient validation check for free. _### Naming changes | Before | After | |----------------------------|-----------------------------------| | `CommandQueue` | `spanlatch.Manager` | | "enter the command queue" | "acquire span latches" | | "exit the command queue" | "release span latches" | | "wait for prereq commands" | "wait for latches to be released" | The use of the word "latch" is based on the definition of latches presented by Goetz Graefe in https://15721.courses.cs.cmu.edu/spring2016/papers/a16-graefe.pdf (see https://i.stack.imgur.com/fSRzd.png). An important reason for avoiding the word "lock" here is that it is critical for understanding that we don't confuse the operational locking performed by the CommandQueue/spanlatch.Manager with the transaction-scoped locking enforced by intents and our transactional concurrency control model. _### Microbenchmarks NOTE: these are single-threaded benchmarks that don't benefit at all from the concurrency improvements enabled by this new structure. ``` name cmdq time/op spanlatch time/op delta ReadOnlyMix/size=1-4 897ns ±21% 917ns ±18% ~ (p=0.897 n=8+10) ReadOnlyMix/size=4-4 827ns ±22% 772ns ±15% ~ (p=0.448 n=10+10) ReadOnlyMix/size=16-4 905ns ±19% 770ns ±10% -14.90% (p=0.004 n=10+10) ReadOnlyMix/size=64-4 907ns ±20% 730ns ±15% -19.51% (p=0.001 n=10+10) ReadOnlyMix/size=128-4 926ns ±17% 731ns ±11% -21.04% (p=0.000 n=9+10) ReadOnlyMix/size=256-4 977ns ±19% 726ns ± 9% -25.65% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 12.5µs ± 4% 0.7µs ±17% -94.70% (p=0.000 n=8+9) ReadWriteMix/readsPerWrite=1-4 8.18µs ± 5% 0.63µs ± 6% -92.24% (p=0.000 n=10+9) ReadWriteMix/readsPerWrite=4-4 3.80µs ± 2% 0.66µs ± 5% -82.58% (p=0.000 n=8+10) ReadWriteMix/readsPerWrite=16-4 1.82µs ± 2% 0.70µs ± 5% -61.43% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 894ns ±12% 514ns ± 6% -42.48% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 717ns ± 5% 472ns ± 1% -34.21% (p=0.000 n=10+8) ReadWriteMix/readsPerWrite=256-4 607ns ± 5% 453ns ± 3% -25.35% (p=0.000 n=7+10) name cmdq alloc/op spanlatch alloc/op delta ReadOnlyMix/size=1-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=4-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=16-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=64-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=128-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=256-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 915B ± 0% 144B ± 0% -84.26% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 730B ± 0% 144B ± 0% -80.29% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 486B ± 0% 144B ± 0% -70.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 350B ± 0% 144B ± 0% -58.86% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 222B ± 0% 144B ± 0% -35.14% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 199B ± 0% 144B ± 0% -27.64% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=256-4 188B ± 0% 144B ± 0% -23.40% (p=0.000 n=10+10) name cmdq allocs/op spanlatch allocs/op delta ReadOnlyMix/size=1-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=4-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=16-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=0-4 34.0 ± 0% 1.0 ± 0% -97.06% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 22.0 ± 0% 1.0 ± 0% -95.45% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 10.0 ± 0% 1.0 ± 0% -90.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 4.00 ± 0% 1.00 ± 0% -75.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ``` Release note: None
{kind=link}
Informs cockroachdb#4768. Informs cockroachdb#31904. This change was inspired by cockroachdb#31904 and is a progression of the thinking started in cockroachdb#4768 (comment). The change introduces `spanlatch.Manager`, which will replace the `CommandQueue` **in a future PR**. The new type isn't hooked up yet because doing so will require a lot of plumbing changes in that storage package that are best kept in a separate PR. The structure uses a new strategy that reduces lock contention, simplifies the code, avoids allocations, and makes cockroachdb#31904 easier to implement. The primary objective, reducing lock contention, is addressed by minimizing the amount of work we perform under the exclusive "sequencing" mutex while locking the structure. This is made possible by employing a copy-on-write strategy. Before this change, commands would lock the queue, create a large slice of prerequisites, insert into the queue and unlock. After the change, commands lock the manager, grab an immutable snapshot of the manager's trees in O(1) time, insert into the manager, and unlock. They can then iterate over the immutable tree snapshot outside of the lock. Effectively, this means that the work performed under lock is linear with respect to the number of spans that a command declares but NO LONGER linear with respect to the number of other commands that it will wait on. This is important because `Replica.beginCmds` repeatedly comes up as the largest source of mutex contention in our system, especially on hot ranges. The use of immutable snapshots also simplifies the code significantly. We're no longer copying our prereqs into a slice so we no longer need to carefully determine which transitive dependencies we do or don't need to wait on explicitly. This also makes lock cancellation trivial because we no longer explicitly hold on to our prereqs at all. Instead, we simply iterate through the snapshot outside of the lock. While rewriting the structure, I also spent some time optimizing its allocations. Under normal operation, acquiring a latch now incurs only a single allocation - that being for the `spanlatch.Guard`. All other allocations are avoided through object pooling where appropriate. The overhead of using a copy-on-write technique is almost entirely avoided by atomically reference counting btree nodes, which allows us to release them back into the btree node pools when they're no longer references by any btree snapshots. This means that we don't expect any allocations when inserting into the internal trees, even with the COW policy. Finally, this will make the approach taken in cockroachdb#31904 much more natural. Instead of tracking dependents and prerequisites for speculative reads and then iterating through them to find overlaps after, we can use the immutable snapshots directly! We can grab a snapshot and sequence ourselves as usual, but avoid waiting for prereqs. We then execute optimistically before finally checking whether we overlapped any of our prereqs. The great thing about this is that we already have the prereqs in an interval tree structure, so we get an efficient validation check for free. _### Naming changes | Before | After | |----------------------------|-----------------------------------| | `CommandQueue` | `spanlatch.Manager` | | "enter the command queue" | "acquire span latches" | | "exit the command queue" | "release span latches" | | "wait for prereq commands" | "wait for latches to be released" | The use of the word "latch" is based on the definition of latches presented by Goetz Graefe in https://15721.courses.cs.cmu.edu/spring2016/papers/a16-graefe.pdf (see https://i.stack.imgur.com/fSRzd.png). An important reason for avoiding the word "lock" here is that it is critical for understanding that we don't confuse the operational locking performed by the CommandQueue/spanlatch.Manager with the transaction-scoped locking enforced by intents and our transactional concurrency control model. _### Microbenchmarks NOTE: these are single-threaded benchmarks that don't benefit at all from the concurrency improvements enabled by this new structure. ``` name cmdq time/op spanlatch time/op delta ReadOnlyMix/size=1-4 897ns ±21% 917ns ±18% ~ (p=0.897 n=8+10) ReadOnlyMix/size=4-4 827ns ±22% 772ns ±15% ~ (p=0.448 n=10+10) ReadOnlyMix/size=16-4 905ns ±19% 770ns ±10% -14.90% (p=0.004 n=10+10) ReadOnlyMix/size=64-4 907ns ±20% 730ns ±15% -19.51% (p=0.001 n=10+10) ReadOnlyMix/size=128-4 926ns ±17% 731ns ±11% -21.04% (p=0.000 n=9+10) ReadOnlyMix/size=256-4 977ns ±19% 726ns ± 9% -25.65% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 12.5µs ± 4% 0.7µs ±17% -94.70% (p=0.000 n=8+9) ReadWriteMix/readsPerWrite=1-4 8.18µs ± 5% 0.63µs ± 6% -92.24% (p=0.000 n=10+9) ReadWriteMix/readsPerWrite=4-4 3.80µs ± 2% 0.66µs ± 5% -82.58% (p=0.000 n=8+10) ReadWriteMix/readsPerWrite=16-4 1.82µs ± 2% 0.70µs ± 5% -61.43% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 894ns ±12% 514ns ± 6% -42.48% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 717ns ± 5% 472ns ± 1% -34.21% (p=0.000 n=10+8) ReadWriteMix/readsPerWrite=256-4 607ns ± 5% 453ns ± 3% -25.35% (p=0.000 n=7+10) name cmdq alloc/op spanlatch alloc/op delta ReadOnlyMix/size=1-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=4-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=16-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=64-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=128-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=256-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 915B ± 0% 144B ± 0% -84.26% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 730B ± 0% 144B ± 0% -80.29% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 486B ± 0% 144B ± 0% -70.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 350B ± 0% 144B ± 0% -58.86% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 222B ± 0% 144B ± 0% -35.14% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 199B ± 0% 144B ± 0% -27.64% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=256-4 188B ± 0% 144B ± 0% -23.40% (p=0.000 n=10+10) name cmdq allocs/op spanlatch allocs/op delta ReadOnlyMix/size=1-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=4-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=16-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=0-4 34.0 ± 0% 1.0 ± 0% -97.06% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 22.0 ± 0% 1.0 ± 0% -95.45% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 10.0 ± 0% 1.0 ± 0% -90.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 4.00 ± 0% 1.00 ± 0% -75.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ``` Release note: None
Informs cockroachdb#4768. Informs cockroachdb#31904. This change was inspired by cockroachdb#31904 and is a progression of the thinking started in cockroachdb#4768 (comment). The change introduces `spanlatch.Manager`, which will replace the `CommandQueue` **in a future PR**. The new type isn't hooked up yet because doing so will require a lot of plumbing changes in that storage package that are best kept in a separate PR. The structure uses a new strategy that reduces lock contention, simplifies the code, avoids allocations, and makes cockroachdb#31904 easier to implement. The primary objective, reducing lock contention, is addressed by minimizing the amount of work we perform under the exclusive "sequencing" mutex while locking the structure. This is made possible by employing a copy-on-write strategy. Before this change, commands would lock the queue, create a large slice of prerequisites, insert into the queue and unlock. After the change, commands lock the manager, grab an immutable snapshot of the manager's trees in O(1) time, insert into the manager, and unlock. They can then iterate over the immutable tree snapshot outside of the lock. Effectively, this means that the work performed under lock is linear with respect to the number of spans that a command declares but NO LONGER linear with respect to the number of other commands that it will wait on. This is important because `Replica.beginCmds` repeatedly comes up as the largest source of mutex contention in our system, especially on hot ranges. The use of immutable snapshots also simplifies the code significantly. We're no longer copying our prereqs into a slice so we no longer need to carefully determine which transitive dependencies we do or don't need to wait on explicitly. This also makes lock cancellation trivial because we no longer explicitly hold on to our prereqs at all. Instead, we simply iterate through the snapshot outside of the lock. While rewriting the structure, I also spent some time optimizing its allocations. Under normal operation, acquiring a latch now incurs only a single allocation - that being for the `spanlatch.Guard`. All other allocations are avoided through object pooling where appropriate. The overhead of using a copy-on-write technique is almost entirely avoided by atomically reference counting btree nodes, which allows us to release them back into the btree node pools when they're no longer references by any btree snapshots. This means that we don't expect any allocations when inserting into the internal trees, even with the COW policy. Finally, this will make the approach taken in cockroachdb#31904 much more natural. Instead of tracking dependents and prerequisites for speculative reads and then iterating through them to find overlaps after, we can use the immutable snapshots directly! We can grab a snapshot and sequence ourselves as usual, but avoid waiting for prereqs. We then execute optimistically before finally checking whether we overlapped any of our prereqs. The great thing about this is that we already have the prereqs in an interval tree structure, so we get an efficient validation check for free. _### Naming changes | Before | After | |----------------------------|-----------------------------------| | `CommandQueue` | `spanlatch.Manager` | | "enter the command queue" | "acquire span latches" | | "exit the command queue" | "release span latches" | | "wait for prereq commands" | "wait for latches to be released" | The use of the word "latch" is based on the definition of latches presented by Goetz Graefe in https://15721.courses.cs.cmu.edu/spring2016/papers/a16-graefe.pdf (see https://i.stack.imgur.com/fSRzd.png). An important reason for avoiding the word "lock" here is that it is critical for understanding that we don't confuse the operational locking performed by the CommandQueue/spanlatch.Manager with the transaction-scoped locking enforced by intents and our transactional concurrency control model. _### Microbenchmarks NOTE: these are single-threaded benchmarks that don't benefit at all from the concurrency improvements enabled by this new structure. ``` name cmdq time/op spanlatch time/op delta ReadOnlyMix/size=1-4 897ns ±21% 917ns ±18% ~ (p=0.897 n=8+10) ReadOnlyMix/size=4-4 827ns ±22% 772ns ±15% ~ (p=0.448 n=10+10) ReadOnlyMix/size=16-4 905ns ±19% 770ns ±10% -14.90% (p=0.004 n=10+10) ReadOnlyMix/size=64-4 907ns ±20% 730ns ±15% -19.51% (p=0.001 n=10+10) ReadOnlyMix/size=128-4 926ns ±17% 731ns ±11% -21.04% (p=0.000 n=9+10) ReadOnlyMix/size=256-4 977ns ±19% 726ns ± 9% -25.65% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 12.5µs ± 4% 0.7µs ±17% -94.70% (p=0.000 n=8+9) ReadWriteMix/readsPerWrite=1-4 8.18µs ± 5% 0.63µs ± 6% -92.24% (p=0.000 n=10+9) ReadWriteMix/readsPerWrite=4-4 3.80µs ± 2% 0.66µs ± 5% -82.58% (p=0.000 n=8+10) ReadWriteMix/readsPerWrite=16-4 1.82µs ± 2% 0.70µs ± 5% -61.43% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 894ns ±12% 514ns ± 6% -42.48% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 717ns ± 5% 472ns ± 1% -34.21% (p=0.000 n=10+8) ReadWriteMix/readsPerWrite=256-4 607ns ± 5% 453ns ± 3% -25.35% (p=0.000 n=7+10) name cmdq alloc/op spanlatch alloc/op delta ReadOnlyMix/size=1-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=4-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=16-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=64-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=128-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadOnlyMix/size=256-4 223B ± 0% 191B ± 0% -14.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=0-4 915B ± 0% 144B ± 0% -84.26% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 730B ± 0% 144B ± 0% -80.29% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 486B ± 0% 144B ± 0% -70.35% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 350B ± 0% 144B ± 0% -58.86% (p=0.000 n=9+10) ReadWriteMix/readsPerWrite=64-4 222B ± 0% 144B ± 0% -35.14% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=128-4 199B ± 0% 144B ± 0% -27.64% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=256-4 188B ± 0% 144B ± 0% -23.40% (p=0.000 n=10+10) name cmdq allocs/op spanlatch allocs/op delta ReadOnlyMix/size=1-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=4-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=16-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=0-4 34.0 ± 0% 1.0 ± 0% -97.06% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=1-4 22.0 ± 0% 1.0 ± 0% -95.45% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=4-4 10.0 ± 0% 1.0 ± 0% -90.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=16-4 4.00 ± 0% 1.00 ± 0% -75.00% (p=0.000 n=10+10) ReadWriteMix/readsPerWrite=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ``` Release note: None
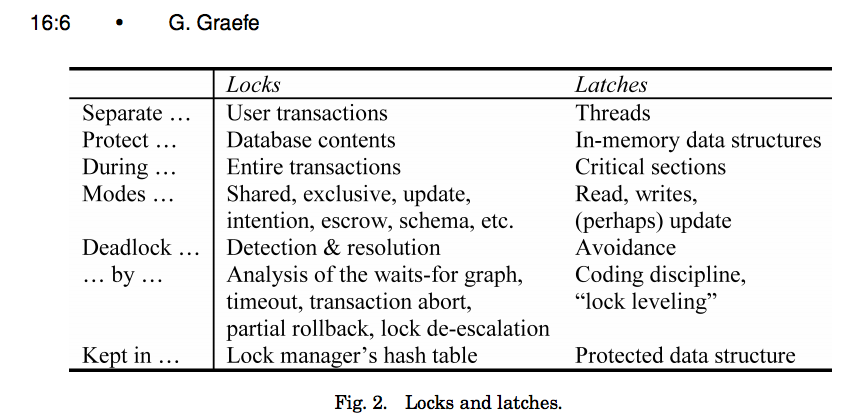
31997: storage/spanlatch: create spanlatch.Manager using immutable btrees r=nvanbenschoten a=nvanbenschoten Informs #4768. Informs #31904. This change was inspired by #31904 and is a progression of the thinking started in #4768 (comment). The change introduces `spanlatch.Manager`, which will replace the `CommandQueue` **in a future PR**. The new type isn't hooked up yet because doing so will require a lot of plumbing changes in that storage package that are best kept in a separate PR. The structure uses a new strategy that reduces lock contention, simplifies the code, avoids allocations, and makes #31904 easier to implement. The primary objective, reducing lock contention, is addressed by minimizing the amount of work we perform under the exclusive "sequencing" mutex while locking the structure. This is made possible by employing a copy-on-write strategy. Before this change, commands would lock the queue, create a large slice of prerequisites, insert into the queue and unlock. After the change, commands lock the manager, grab an immutable snapshot of the manager's trees in O(1) time, insert into the manager, and unlock. They can then iterate over the immutable tree snapshot outside of the lock. Effectively, this means that the work performed under lock is linear with respect to the number of spans that a command declares but NO LONGER linear with respect to the number of other commands that it will wait on. This is important because `Replica.beginCmds` repeatedly comes up as the largest source of mutex contention in our system, especially on hot ranges. The use of immutable snapshots also simplifies the code significantly. We're no longer copying our prereqs into a slice so we no longer need to carefully determine which transitive dependencies we do or don't need to wait on explicitly. This also makes lock cancellation trivial because we no longer explicitly hold on to our prereqs at all. Instead, we simply iterate through the snapshot outside of the lock. While rewriting the structure, I also spent some time optimizing its allocations. Under normal operation, acquiring a latch now incurs only a single allocation - that being for the `spanlatch.Guard`. All other allocations are avoided through object pooling where appropriate. The overhead of using a copy-on-write technique is almost entirely avoided by atomically reference counting immutable btree nodes, which allows us to release them back into the btree node pools when they're no longer needed. This means that we don't expect any allocations when inserting into the internal trees, even with the copy-on-write policy. Finally, this will make the approach taken in #31904 much more natural. Instead of tracking dependents and prerequisites for speculative reads and then iterating through them to find overlaps after, we can use the immutable snapshots directly! We can grab a snapshot and sequence ourselves as usual, but avoid waiting for prereqs. We then execute optimistically before finally checking whether we overlapped any of our prereqs. The great thing about this is that we already have the prereqs in an interval tree structure, so we get an efficient validation check for free. ### Naming changes | Before | After | |----------------------------|-----------------------------------| | `CommandQueue` | `spanlatch.Manager` | | "enter the command queue" | "acquire span latches" | | "exit the command queue" | "release span latches" | | "wait for prereq commands" | "wait for latches to be released" | The use of the word "latch" is based on the definition of latches presented by Goetz Graefe in https://15721.courses.cs.cmu.edu/spring2016/papers/a16-graefe.pdf (see https://i.stack.imgur.com/fSRzd.png). An important reason for avoiding the word "lock" here is that it is critical for understanding that we don't confuse the operational locking performed by the CommandQueue/spanlatch.Manager with the transaction-scoped locking enforced by intents and our transactional concurrency control model. ### Microbenchmarks NOTE: these are single-threaded benchmarks that don't benefit at all from the concurrency improvements enabled by this new structure. ``` name old time/op new time/op delta ReadOnlyMix/size=1-4 706ns ±20% 404ns ±10% -42.81% (p=0.008 n=5+5) ReadOnlyMix/size=4-4 649ns ±23% 382ns ± 5% -41.13% (p=0.008 n=5+5) ReadOnlyMix/size=16-4 611ns ±16% 367ns ± 5% -39.83% (p=0.008 n=5+5) ReadOnlyMix/size=64-4 692ns ±14% 370ns ± 1% -46.49% (p=0.016 n=5+4) ReadOnlyMix/size=128-4 637ns ±22% 398ns ±14% -37.48% (p=0.008 n=5+5) ReadOnlyMix/size=256-4 676ns ±15% 385ns ± 4% -43.01% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=0-4 12.2µs ± 4% 0.6µs ±17% -94.85% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=1-4 7.88µs ± 2% 0.55µs ± 7% -92.99% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=4-4 4.19µs ± 3% 0.58µs ± 5% -86.26% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=16-4 2.09µs ± 6% 0.54µs ±13% -74.13% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=64-4 875ns ±17% 423ns ±29% -51.64% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=128-4 655ns ± 6% 362ns ±16% -44.71% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=256-4 549ns ±16% 314ns ±13% -42.73% (p=0.008 n=5+5) name old alloc/op new alloc/op delta ReadOnlyMix/size=1-4 223B ± 0% 160B ± 0% -28.25% (p=0.079 n=4+5) ReadOnlyMix/size=4-4 223B ± 0% 160B ± 0% -28.25% (p=0.008 n=5+5) ReadOnlyMix/size=16-4 223B ± 0% 160B ± 0% -28.25% (p=0.008 n=5+5) ReadOnlyMix/size=64-4 223B ± 0% 160B ± 0% -28.25% (p=0.008 n=5+5) ReadOnlyMix/size=128-4 217B ± 4% 160B ± 0% -26.27% (p=0.008 n=5+5) ReadOnlyMix/size=256-4 223B ± 0% 160B ± 0% -28.25% (p=0.079 n=4+5) ReadWriteMix/readsPerWrite=0-4 1.25kB ± 0% 0.16kB ± 0% -87.15% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=1-4 1.00kB ± 0% 0.16kB ± 0% -84.00% (p=0.079 n=4+5) ReadWriteMix/readsPerWrite=4-4 708B ± 0% 160B ± 0% -77.40% (p=0.079 n=4+5) ReadWriteMix/readsPerWrite=16-4 513B ± 0% 160B ± 0% -68.81% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=64-4 264B ± 0% 160B ± 0% -39.39% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=128-4 221B ± 0% 160B ± 0% -27.60% (p=0.079 n=4+5) ReadWriteMix/readsPerWrite=256-4 198B ± 0% 160B ± 0% -19.35% (p=0.008 n=5+5) name old allocs/op new allocs/op delta ReadOnlyMix/size=1-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=4-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=16-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=64-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadOnlyMix/size=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=0-4 38.0 ± 0% 1.0 ± 0% -97.37% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=1-4 24.0 ± 0% 1.0 ± 0% -95.83% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=4-4 12.0 ± 0% 1.0 ± 0% -91.67% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=16-4 5.00 ± 0% 1.00 ± 0% -80.00% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=64-4 2.00 ± 0% 1.00 ± 0% -50.00% (p=0.008 n=5+5) ReadWriteMix/readsPerWrite=128-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ReadWriteMix/readsPerWrite=256-4 1.00 ± 0% 1.00 ± 0% ~ (all equal) ``` There are a few interesting things to point about about these benchmark results: - The `ReadOnlyMix` results demonstrate a fixed improvement, regardless of size. This is due to the replacement of the hash-map with a linked-list for the readSet structure. - The `ReadWriteMix` is more interesting. We see that the spanlatch implementation is faster across the board. This is especially true with a high write/read ratio. - We see that the allocated memory stays constant regardless of the write/read ratio in the spanlatch implementation. This is due to the memory recylcing that it performs on btree nodes. It is not the case for the CommandQueue implementation. Release note: None 32416: scripts: enhance the release notes r=knz a=knz Fixes #25180. With this the amount of release notes for the first 2.2 alpha in cockroachdb/docs#4051 is reduced to just under two pages. Also this PR makes it easier to monitor progress during the execution of the script. Co-authored-by: Nathan VanBenschoten <nvanbenschoten@gmail.com> Co-authored-by: Raphael 'kena' Poss <knz@cockroachlabs.com>
Fixes cockroachdb#9521. Supersedes cockroachdb#31904. SQL has a tendency to create scans which cover a range's entire key span, though looking only to return a finite number of results. These requests end up blocking on writes that are holding latches over keys that the scan will not actually touch. In reality, when there is a scan with a limit, the actual affected key span ends up being a small subset of the range's key span. This change creates a new "optimistic evaluation" path for read-only requests. When evaluating optimistically, the batch will sequence itself with the latch manager, but will not wait to acquire all of its latches. Instead, it begins evaluating immediately and verifies that it would not have needed to wait on any latch acquisitions after-the-fact. When performing this verification, it uses knowledge about the limited set of keys that the scan actually looked at. If there are no conflicts, the scan succeeds. If there are conflicts, the request waits for all of its latch acquisition attempts to finish and re-evaluates. This PR replaces cockroachdb#31904. The major difference between the two is that this PR exploits the structure of the latch manager to efficiently perform optimistic latch acquisition and after-the-fact verification of conflicts. Doing this requires keeping no extra state because it uses the immutable snapshots that the latch manager now captures during sequencing. The other major difference is that this PR does not release latches after a failed optimistic evaluation. NOTE: a prevalent theory of the pathological case with this behavior was that overestimated read latches would serialize with write latches, causing all requests on a range to serialize. I wasn't seeing this in practice. It turns out that the "timestamp awareness" in the latch manager should avoid this behavior in most cases because later writes will have higher timestamps than earlier reads. The effect of this is that they won't be considered to interfere by the latch manager. Still, large clusters with a high amount of clock skew could see a bounded variant of this situation. _### Benchmark Results ``` name old ops/sec new ops/sec delta kv95/cores=16/nodes=3/splits=3 51.9k ± 0% 51.7k ± 1% ~ (p=0.400 n=3+3) kvS70-L1/cores=16/nodes=3/splits=3 24.1k ± 4% 27.7k ± 1% +14.75% (p=0.100 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 24.5k ± 1% 27.5k ± 1% +12.08% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 16.0k ± 1% 16.6k ± 2% +3.79% (p=0.100 n=3+3) name old p50(ms) new p50(ms) delta kv95/cores=16/nodes=3/splits=3 0.70 ± 0% 0.70 ± 0% ~ (all equal) kvS70-L1/cores=16/nodes=3/splits=3 1.07 ± 6% 0.90 ± 0% -15.62% (p=0.100 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 1.10 ± 0% 0.90 ± 0% -18.18% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 1.80 ± 0% 1.67 ± 4% -7.41% (p=0.100 n=3+3) name old p99(ms) new p99(ms) delta kv95/cores=16/nodes=3/splits=3 1.80 ± 0% 1.80 ± 0% ~ (all equal) kvS70-L1/cores=16/nodes=3/splits=3 5.77 ±32% 4.70 ± 0% ~ (p=0.400 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 5.00 ± 0% 4.70 ± 0% -6.00% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 6.90 ± 3% 7.33 ± 8% ~ (p=0.400 n=3+3) ``` _S<num> = --span-percent=<num>, L<num> = --span-limit=<num>_ Release note (performance improvement): improved performance on workloads which mix OLAP queries with inserts and updates.
Fixes cockroachdb#9521. Supersedes cockroachdb#31904. SQL has a tendency to create scans which cover a range's entire key span, though looking only to return a finite number of results. These requests end up blocking on writes that are holding latches over keys that the scan will not actually touch. In reality, when there is a scan with a limit, the actual affected key span ends up being a small subset of the range's key span. This change creates a new "optimistic evaluation" path for read-only requests. When evaluating optimistically, the batch will sequence itself with the latch manager, but will not wait to acquire all of its latches. Instead, it begins evaluating immediately and verifies that it would not have needed to wait on any latch acquisitions after-the-fact. When performing this verification, it uses knowledge about the limited set of keys that the scan actually looked at. If there are no conflicts, the scan succeeds. If there are conflicts, the request waits for all of its latch acquisition attempts to finish and re-evaluates. This PR replaces cockroachdb#31904. The major difference between the two is that this PR exploits the structure of the latch manager to efficiently perform optimistic latch acquisition and after-the-fact verification of conflicts. Doing this requires keeping no extra state because it uses the immutable snapshots that the latch manager now captures during sequencing. The other major difference is that this PR does not release latches after a failed optimistic evaluation. NOTE: a prevalent theory of the pathological case with this behavior was that overestimated read latches would serialize with write latches, causing all requests on a range to serialize. I wasn't seeing this in practice. It turns out that the "timestamp awareness" in the latch manager should avoid this behavior in most cases because later writes will have higher timestamps than earlier reads. The effect of this is that they won't be considered to interfere by the latch manager. Still, large clusters with a high amount of clock skew could see a bounded variant of this situation. _### Benchmark Results ``` name old ops/sec new ops/sec delta kv95/cores=16/nodes=3/splits=3 51.9k ± 0% 51.7k ± 1% ~ (p=0.400 n=3+3) kvS70-L1/cores=16/nodes=3/splits=3 24.1k ± 4% 27.7k ± 1% +14.75% (p=0.100 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 24.5k ± 1% 27.5k ± 1% +12.08% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 16.0k ± 1% 16.6k ± 2% +3.79% (p=0.100 n=3+3) name old p50(ms) new p50(ms) delta kv95/cores=16/nodes=3/splits=3 0.70 ± 0% 0.70 ± 0% ~ (all equal) kvS70-L1/cores=16/nodes=3/splits=3 1.07 ± 6% 0.90 ± 0% -15.62% (p=0.100 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 1.10 ± 0% 0.90 ± 0% -18.18% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 1.80 ± 0% 1.67 ± 4% -7.41% (p=0.100 n=3+3) name old p99(ms) new p99(ms) delta kv95/cores=16/nodes=3/splits=3 1.80 ± 0% 1.80 ± 0% ~ (all equal) kvS70-L1/cores=16/nodes=3/splits=3 5.77 ±32% 4.70 ± 0% ~ (p=0.400 n=3+3) kvS70-L5/cores=16/nodes=3/splits=3 5.00 ± 0% 4.70 ± 0% -6.00% (p=0.100 n=3+3) kvS70-L1000/cores=16/nodes=3/splits=3 6.90 ± 3% 7.33 ± 8% ~ (p=0.400 n=3+3) ``` _S<num> = --span-percent=<num>, L<num> = --span-limit=<num>_ Release note (performance improvement): improved performance on workloads which mix OLAP queries with inserts and updates.
|
|
SQL has a tendancy to create scans which cover a range's entire key
span, though looking only to return a finite number of results. These
requests end up blocking writes in the command queue, which block
other reads, causing requsets to effectively serialize. In reality,
when there is a scan with a limit, the actual affected key span ends
up being a small subset of the range's key span.
This change creates a new "pre-evaluation" execution path for read-
only requests. When pre-evaluating, the batch still interacts with
the command queue, but it neither waits for pre-requisites nor causes
successor, dependent write batches from waiting on it. Instead, any
prereqs or dependents are tracked while the read-only batch is
immediately evaluated without blocking. On successful evaluation,
the actual span(s) covered and recorded in the read-only batch's
BatchResponseare compared to the pre-requisite and dependentcommands. If there is no overlap, the timestamp cache is updated and
the read-only batch response returned to the caller. If there is
overlap, then the read-only batch is re-executed, but with the
pre-evaluation option disabled, so that it proceeds to interact with
the command queue in the traditional fashion, waiting on prereqs
and making dependents wait on it.
Release note: improved performance on workloads which mix OLAP queries
with updates.