The R code for this post is available on github, and is based on Rand Wilcox’s WRS R package, with extra visualisation functions written using ggplot2. The R code for the 2013 percentile bootstrap version of the shift function was also covered here and here. Matlab code is described in another post.
UPDATE: The shift function and its cousin the difference asymmetry function are described in a review article with many examples. And a Bayesian shift function is now available! The hierarchical shift function provides a powerful alternative to the t-test.
In neuroscience & psychology, group comparison is usually an exercise that involves comparing two typical observations. This is most of the time achieved using a t-test on means. This standard procedure makes very strong assumptions:
- the distributions differ only in central tendency, not in other aspects;
- the typical observation in each distribution can be summarised by the mean;
- the t-test is sufficient to detect changes in location.
As we saw previously, t-tests on means are not robust. In addition, there is no reason a priori to assume that two distributions differ only in the location of the bulk of the observations. Effects can occur in the tails of the distributions too: for instance a particular intervention could have an effect only in animals with a certain hormonal level at baseline; a drug could help participants with severe symptoms, but not others with milder symptoms… Because effects are not necessarily homogenous among participants, it is useful to have appropriate tools at hand, to determine how, and by how much, two distributions differ. Here we’re going to consider a powerful family of tools that are robust and let us compare entire distributions: shift functions.
A more systematic way to characterise how two independent distributions differ was originally proposed by Doksum (Doksum, 1974; Doksum & Sievers, 1976; Doksum, 1977): to plot the difference between the quantiles of two distributions as a function of the quantiles of one group. The original shift function approach is implemented in the functions sband and wband in Rand Wilcox’s WRS R package.
In 1995, Wilcox proposed an alternative technique which has better probability coverage and potentially more power than Doksum & Sievers’ approach. Wilcox’s technique:
- uses the Harrell-Davis quantile estimator;
- computes confidence intervals of the decile differences with a bootstrap estimation of the standard error of the deciles;
- controls for multiple comparisons so that the type I error rate remains around 0.05 across the 9 confidence intervals. This means that the confidence intervals are a bit larger than what they would be if only one decile was compared, so that the long-run probability of a type I error across all 9 comparisons remains near 0.05;
- is implemented in the
shifthd function.
Let’s start with an extreme and probably unusual example, in which two distributions differ in spread, not in location (Figure 1). In that case, any test of central tendency will fail to reject, but it would be wrong to conclude that the two distributions do not differ. In fact, a Kolmogorov-Smirnov test reveals a significant effect, and several measures of effect sizes would suggest non-trivial effects. However, a significant KS test just tells us that the two distributions differ, not how.

Figure 1. Two distributions that differ in spread A Kernel density estimates for the groups. B Shift function. Group 1 – group 2 is plotted along the y-axis for each decile (white disks), as a function of group 1 deciles. For each decile difference, the vertical line indicates its 95% bootstrap confidence interval. When a confidence interval does not include zero, the difference is considered significant in a frequentist sense.
The shift function can help us understand and quantify how the two distributions differ. The shift function describes how one distribution should be re-arranged to match the other one: it estimates how and by how much one distribution must be shifted. In Figure 1, I’ve added annotations to help understand the link between the KDE in panel A and the shift function in panel B. The shift function shows the decile differences between group 1 and group 2, as a function of group 1 deciles. The deciles for each group are marked by coloured vertical lines in panel A. The first decile of group 1 is slightly under 5, which can be read in the top KDE of panel A, and on the x-axis of panel B. The first decile of group 2 is lower. As a result, the first decile difference between group 1 and group 2 is positive, as indicated by a positive value around 0.75 in panel B, as marked by an upward arrow and a + symbol. The same symbol appears in panel A, linking the deciles from the two groups: it shows that to match the first deciles, group 2’s first decile needs to be shifted up. Deciles 2, 3 & 4 show the same pattern, but with progressively weaker effect sizes. Decile 5 is well centred, suggesting that the two distributions do not differ in central tendency. As we move away from the median, we observe progressively larger negative differences, indicating that to match the right tails of the two groups, group 2 needs to be shifted to the left, towards smaller values – hence the negative sign.
To get a good understanding of the shift function, let’s look at its behaviour in several other clear-cut situations. First, let’s consider a situation in which two distributions differ in location (Figure 2). In that case, a t-test is significant, but again, it’s not the full story. The shift function looks like this:

Figure 2. Complete shift between two distributions
What’s happening? All the differences between deciles are negative and around -0.45. Wilcox (2012) defines such systematic effect has the hallmark of a completely effective method. In other words, there is a complete and seemingly uniform shift between the two distributions.
In the next example (Figure 3), only the right tails differ, which is captured by significant differences for deciles 6 to 9. This is a case described by Wilcox (2012) as involving a partially effective experimental manipulation.

Figure 3. Positive right tail shift
Figure 4 also shows a right tail shift, this time in the negative direction. I’ve also scaled the distributions so they look a bit like reaction time distributions. It would be much more informative to use shift functions in individual participants to study how RT distributions differ between conditions, instead of summarising each distribution by its mean (sigh)!

Figure 4. Negative right tail shift
Figure 5 shows two large samples drawn from a standard normal population. As expected, the shift function suggests that we do not have enough evidence to conclude that the two distributions differ. The shift function does look bumpy tough, potentially suggesting local differences – so keep that in mind when you plug-in your own data.

Figure 5. No difference?
And be careful not to over-interpret the shift function: the lack of significant differences should not be used to conclude that we have evidence for the lack of effect; indeed, failure to reject in the frequentist sense can still be associated with non-trivial evidence against the null – it depends on prior results (Wagenmakers, 2007).
So far, we’ve looked at simulated examples involving large sample sizes. We now turn to a few real-data examples.
Doksum & Sievers (1976) describe an example in which two groups of rats were kept in an environment with or without ozone for 7 days and their weight gains measured (Figure 6). The shift function suggests two results: overall, ozone reduces weight gain; ozone might promote larger weight gains in animals gaining the most weight. However, these conclusions are only tentative given the small sample size, which explains the large confidence intervals.

Figure 6. Weight gains A Because the sample sizes are much smaller than in the previous examples, the distributions are illustrated using 1D scatterplots. The deciles are marked by grey vertical lines, with lines for the 0.5 quantiles. B Shift function.
Let’s consider another example used in (Doksum, 1974; Doksum, 1977), concerning the survival time in days of 107 control guinea pigs and 61 guinea pigs treated with a heavy dose of tubercle bacilli (Figure 7). Relative to controls, the animals that died the earliest tended to live longer in the treatment group, suggesting that the treatment was beneficial to the weaker animals (decile 1). However, the treatment was harmful to animals with control survival times larger than about 200 days (deciles 4-9). Thus, this is a case where the treatment has very different effects on different animals. As noted by Doksum, the same experiment was actually performed 4 times, each time giving similar results.

Figure 7. Survival time
Shift function for dependent groups
All the previous examples were concerned with independent groups. There is a version of the shift function for dependent groups implemented in shiftdhd. We’re going to apply it to ERP onsets from an object detection task (Bieniek et al., 2015). In that study, 74 of our 120 participants were tested twice, to assess the test-retest reliability of different measurements, including onsets. Typically, test-retest assessment is performed using a correlation. However, we care about the units (ms), which a correlation would get rid of, and we had a more specific hypothesis, which a correlation cannot test; so we used a shift function (Figure 8). If you look at the distributions of onsets across participants, you will see that it is overall positively skewed, and with a few participants with particularly early or late onsets. With the shift function, we wanted to test for the overall reliability of the results, but also in particular the reliability of the left and right tails: if early onsets in session 1 were due to chance, we would expect session 2 estimates to be overall larger (shifted to the right); similarly, if late onsets in session 1 were due to chance, we would expect session 2 estimates to be overall smaller (shifted to the left). The shift function does not provide enough evidence to suggest a uniform or non-uniform shift – but we would probably need many more observations to make a strong claim.

Figure 8. ERP onsets
Because we’re dealing with a paired design, the illustration of the marginal distributions in Figure 8 is insufficient: we should illustrate the distribution of pairwise differences too, as shown in Figure 9.

Figure 9. ERP onsets with KDE of pairwise differences
Figure 10 provides an alternative representation of the distribution of pairwise differences using a violin plot.

Figure 10. ERP onsets with violin plot of pairwise differences
Figure 11 uses a 1D scatterplot (strip chart).
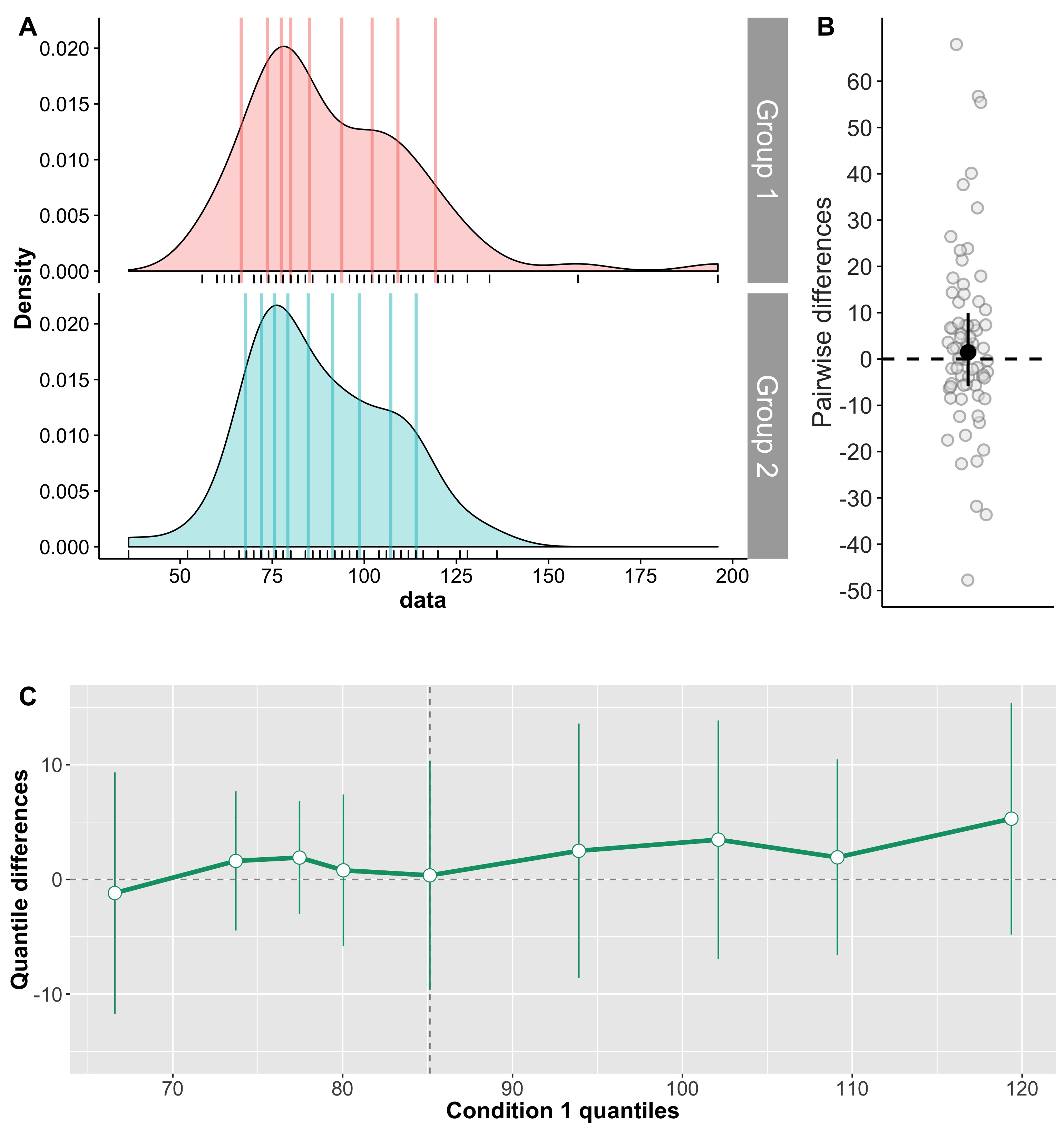
Figure 11. ERP onsets with 1D scatterplot of pairwise differences
Shift function for other quantiles
Although powerful, Wilcox’s 1995 technique is not perfect, because it:
- is limited to the deciles;
- can only be used with alpha = 0.05;
- does not work well with tied values.
More recently, Wilcox’s proposed a new version of the shift function that uses a straightforward percentile bootstrap (Wilcox & Erceg-Hurn, 2012; Wilcox et al., 2014). This new approach:
- allows tied values;
- can be applied to any quantile;
- can have more power when looking at extreme quantiles (<=0.1, or >=0.9).
- is implemented in
qcomhd for independent groups;
- is implemented in
Dqcomhd for dependent groups.
Examples are provided in the R script for this post.
In the percentile bootstrap version of the shift function, p values are corrected, but not the confidence intervals. For dependent variables, Wilcox & Erceg-Hurn (2012) recommend at least 30 observations to compare the .1 or .9 quantiles. To compare the quartiles, 20 observations appear to be sufficient. For independent variables, Wilcox et al. (2014) make the same recommendations made for dependent groups; in addition, to compare the .95 quantiles, they suggest at least 50 observations per group.
Conclusion
The shift function is a powerful tool that can help you better understand how two distributions differ, and by how much. It provides much more information than the standard t-test approach.
Although currently the shift function only applies to two groups, it can in theory be extended to more complex designs, for instance to quantify interaction effects.
Finally, it would be valuable to make a Bayesian version of the shift function, to focus on effect sizes, model the data, and integrate them with other results.
References
Bieniek, M.M., Bennett, P.J., Sekuler, A.B. & Rousselet, G.A. (2015) A robust and representative lower bound on object processing speed in humans. The European journal of neuroscience.
Doksum, K. (1974) Empirical Probability Plots and Statistical Inference for Nonlinear Models in the two-Sample Case. Annals of Statistics, 2, 267-277.
Doksum, K.A. (1977) Some graphical methods in statistics. A review and some extensions. Statistica Neerlandica, 31, 53-68.
Doksum, K.A. & Sievers, G.L. (1976) Plotting with Confidence – Graphical Comparisons of 2 Populations. Biometrika, 63, 421-434.
Wagenmakers, E.J. (2007) A practical solution to the pervasive problems of p values. Psychonomic bulletin & review, 14, 779-804.
Wilcox, R.R. (1995) Comparing Two Independent Groups Via Multiple Quantiles. Journal of the Royal Statistical Society. Series D (The Statistician), 44, 91-99.
Wilcox, R.R. (2012) Introduction to robust estimation and hypothesis testing. Academic Press, Amsterdam; Boston.
Wilcox, R.R. & Erceg-Hurn, D.M. (2012) Comparing two dependent groups via quantiles. J Appl Stat, 39, 2655-2664.
Wilcox, R.R., Erceg-Hurn, D.M., Clark, F. & Carlson, M. (2014) Comparing two independent groups via the lower and upper quantiles. J Stat Comput Sim, 84, 1543-1551.










































































