Blogs & Thoughts
Astronauts’ favorite key on keyboard.

TL;DR — Four Takeaways from 413K Agent Traces Test early, test often. The single strongest predictor of agent success is the fraction of early bash commands dedicated to testing. This is TDD for AI agents — and it works. Just like humans, agents need to concentrate as well. Agents that scatter edits across 3+ files early are far more likely to fail — a dose-response effect validated across all 3 dataset splits. The Single Responsibility Principle holds for agents. Agents that repeat commands are stuck. Identical bash commands in the early phase predict failure — a genuine behavioral signal, not a task-difficulty confound. Many human SWE “best practices” don’t transfer. View-before-edit, grep-before-edit, incremental TDD cycles — these intuitive principles are confounded or reversed for AI agents. Agents are not junior developers. Every day, thousands of AI agents attempt to solve real software engineering tasks. They read code, run tests, edit files, and submit patches. Each attempt leaves behind a detailed trace — a complete record of every tool call, every bash command, every file read and edit. ...
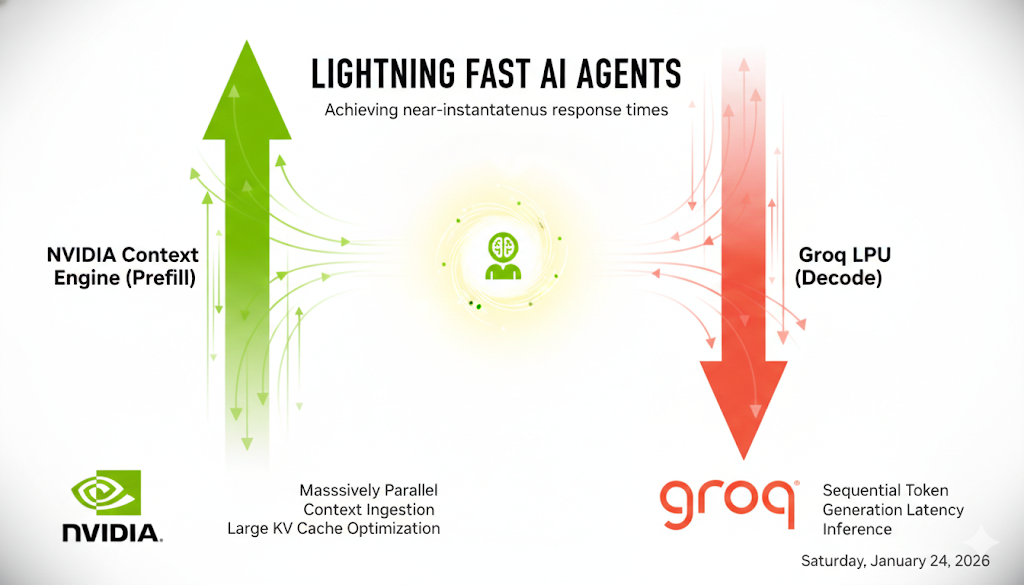
In this blog post, we will discuss Nvidia’s recent announcements at CES and their strategic partnership with Groq, focusing on their strategy to enhance LLM agent inference. We will explore three main aspects: the importance of KV cache hits, the role of SRAM in improving decoding speed, and a proposed hardware-software architecture that potentially speeds up agent inference to real-time. Prerequisite: LLM inference basics. Suggested reading: LLM Inference; KV Cache Offloading with LMCache; LLM Agent with KV Cache ...
Agents are EXPENSIVE. Claude Code takes 1 USD to handle a single issue in a mid-sized public repository when using API. In the same time, it charges 20 USD per month for a subscription license. Why do we still get to use them? Maybe the price war, maybe the crazy debts some companies upstream are carrying, maybe the implicit labeling you are carrying out for the providers. But regardless of the reason behind the pricing, we want to use more these powerful agents. Current models and applications are already capable of handling many complex tasks with minimal human intervention. However, the efficiency of these agents has just rised to our attention. In this blog post, we will discuss why agents are efficiency nightmares, how we can make them (somewhat) better with KV cache management tool like LMCache, and where we could be moving forward for improving agents. ...