-
Notifications
You must be signed in to change notification settings - Fork 527
Feat: Implementation of the DeepSeek blockwise quantization for fp8 tensors #1763
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Merged
danielvegamyhre
merged 18 commits into
pytorch:main
from
the-tuning-machine:feat/blockwise_fp8_quant_triton_gemm_ker
May 12, 2025
Merged
Changes from all commits
Commits
Show all changes
18 commits
Select commit
Hold shift + click to select a range
5d61cbf
Feat: Integration of DeepSeek's blockwise quantization
the-tuning-machine b76b178
Doc: init + linting + readme
the-tuning-machine 4daa787
Feat: adding triton dependency, adaptative testing dtype
the-tuning-machine ee18512
Fix:
the-tuning-machine b9dbfa8
Fix:
the-tuning-machine f5065e9
Fix:
the-tuning-machine e41457c
Fix: triton pytest skip
the-tuning-machine 31ed7c1
Linting
the-tuning-machine 26bb079
Merge branch 'pytorch:main' into feat/blockwise_fp8_quant_triton_gemm…
the-tuning-machine de4118d
Fix:
the-tuning-machine 112f507
Merge branch 'pytorch:main' into feat/blockwise_fp8_quant_triton_gemm…
the-tuning-machine c718e6e
Merge branch 'feat/blockwise_fp8_quant_triton_gemm_ker' of github.com…
the-tuning-machine 0af2b9b
Fix:
the-tuning-machine c2274dc
Optim: fixing poor performance on large M values
the-tuning-machine 35462b4
Merge branch 'pytorch:main' into feat/blockwise_fp8_quant_triton_gemm…
the-tuning-machine 805d731
Merge branch 'feat/blockwise_fp8_quant_triton_gemm_ker' of github.com…
the-tuning-machine 497a515
Fix: skipping blockwise quant precision test for older versions of tr…
the-tuning-machine 10c9436
Bench: incressing the bench range to m=8192
the-tuning-machine File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,130 @@ | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # All rights reserved. | ||
| # | ||
| # This source code is licensed under the BSD 3-Clause license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
|
|
||
|
|
||
| import torch | ||
|
|
||
| if torch.cuda.is_available(): | ||
| import pandas as pd | ||
| from tqdm import tqdm | ||
| from triton.testing import do_bench | ||
|
|
||
| from torchao.float8.float8_utils import compute_error | ||
| from torchao.prototype.blockwise_fp8.blockwise_quantization import ( | ||
| blockwise_fp8_gemm, | ||
| fp8_blockwise_act_quant, | ||
| fp8_blockwise_weight_quant, | ||
| ) | ||
| from torchao.utils import is_sm_at_least_89 | ||
| else: | ||
| raise RuntimeError("This benchmark is only avaible on CUDA hardware") | ||
|
|
||
|
|
||
| def benchmark_microseconds(f, *args, warmup=25, rep=100): | ||
| return ( | ||
| do_bench(lambda: f(*args), warmup=warmup, rep=rep, return_mode="median") * 1e3 | ||
| ) | ||
|
|
||
|
|
||
| def get_blockwise_problem( | ||
| m: int, n: int, k: int, block_size: int, dtype: torch.dtype, device | ||
| ): | ||
| assert n % block_size == 0 and k % block_size == 0, ( | ||
| "N and K dims must be divisible by block_size" | ||
| ) | ||
| assert dtype in [ | ||
| torch.float8_e4m3fn, | ||
| torch.float8_e5m2, | ||
| ], "dtype must be torch.float8_e4m3fn or torch.float8_e5m2" | ||
| dtype_max = torch.finfo(dtype).max | ||
| A = (dtype_max * (2 * torch.rand(m, k, device=device) - 1)).to(dtype) | ||
| A_scale = torch.randn((m, k // block_size), dtype=torch.half, device=device) | ||
| B = (dtype_max * (2 * torch.rand(n, k, device=device) - 1)).to(dtype) | ||
| B_scale = torch.randn( | ||
| (n // block_size, k // block_size), dtype=torch.half, device=device | ||
| ) | ||
|
|
||
| return A, A_scale, B, B_scale | ||
|
|
||
|
|
||
| def benchmark_latency( | ||
| m: int, k: int, n: int, block_size: int, dtype: torch.dtype, device | ||
| ): | ||
| A_ref = torch.randn((m, k), dtype=torch.half, device=device) | ||
| B_ref = torch.randn((n, k), dtype=torch.half, device=device) | ||
| fp16_time = benchmark_microseconds(torch.nn.functional.linear, A_ref, B_ref) | ||
|
|
||
| A, A_scale, B, B_scale = get_blockwise_problem(m, n, k, block_size, dtype, device) | ||
| blockwise_time = benchmark_microseconds( | ||
| blockwise_fp8_gemm, A, A_scale, B, B_scale, block_size | ||
| ) | ||
|
|
||
| return { | ||
| "m": m, | ||
| "k": k, | ||
| "n": n, | ||
| "block_size": block_size, | ||
| "dtype": dtype, | ||
| "fp16_latency (ms)": fp16_time, | ||
| "blockwise_latency (ms)": blockwise_time, | ||
| "blockwise_speedup": fp16_time / blockwise_time, | ||
| } | ||
|
|
||
|
|
||
| def benchmark_precision( | ||
| m: int, k: int, n: int, block_size: int, dtype: torch.dtype, device | ||
| ): | ||
| lin = torch.nn.Linear(k, n, False, device, torch.half) | ||
| A = torch.randn((m, k), dtype=torch.half, device=device) | ||
| W = lin.weight | ||
| output = A @ W.T | ||
|
|
||
| A_q, A_s = fp8_blockwise_act_quant(A, block_size, dtype) | ||
| W_q, W_s = fp8_blockwise_weight_quant(W, block_size, dtype) | ||
| output_blockwise = blockwise_fp8_gemm(A_q, A_s, W_q, W_s, block_size) | ||
|
|
||
| return { | ||
| "m": m, | ||
| "k": k, | ||
| "n": n, | ||
| "block_size": block_size, | ||
| "dtype": dtype, | ||
| "error_blockwise (dB)": compute_error(output, output_blockwise), | ||
| } | ||
|
|
||
|
|
||
| if __name__ == "__main__" and torch.cuda.is_available(): | ||
| device = torch.device("cuda") | ||
| k_vals = (8192, 8192, 8192, 28672) | ||
| n_vals = (8192, 10240, 57344, 8192) | ||
| block_size_vals = (128, 128, 128, 128) | ||
|
|
||
| latency_results = [] | ||
| precision_results = [] | ||
|
|
||
| available_dtypes = ( | ||
| [torch.float8_e4m3fn, torch.float8_e5m2] | ||
| if is_sm_at_least_89() | ||
| else [torch.float8_e5m2] | ||
| ) | ||
| for m in tqdm([1 << i for i in range(14)]): | ||
| for dtype in available_dtypes: | ||
| for n, k, block_size in zip(n_vals, k_vals, block_size_vals): | ||
| latency_results.append( | ||
| benchmark_latency(m, k, n, block_size, dtype, device) | ||
| ) | ||
| precision_results.append( | ||
| benchmark_precision(m, k, n, block_size, dtype, device) | ||
| ) | ||
|
|
||
| df_latency = pd.DataFrame(latency_results) | ||
| df_precision = pd.DataFrame(precision_results) | ||
|
|
||
| df_latency.to_csv("blockwise_triton_latency_results.csv", index=False) | ||
| df_precision.to_csv("blockwise_triton_precision_results.csv", index=False) | ||
|
|
||
| print(df_latency.to_markdown(index=False)) | ||
| print(df_precision.to_markdown(index=False)) | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,72 @@ | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # All rights reserved. | ||
| # | ||
| # This source code is licensed under the BSD 3-Clause license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
|
|
||
| import pytest | ||
| import torch | ||
|
|
||
| from packaging import version | ||
|
|
||
| triton = pytest.importorskip("triton", reason="Triton required to run this test") | ||
|
|
||
| from torchao.prototype.blockwise_fp8.blockwise_quantization import ( | ||
| blockwise_fp8_gemm, | ||
| fp8_blockwise_act_quant, | ||
| fp8_blockwise_weight_dequant, | ||
| fp8_blockwise_weight_quant, | ||
| ) | ||
| from torchao.utils import is_sm_at_least_89 | ||
|
|
||
| BLOCKWISE_SIZE_MNK = [ | ||
| (2, 512, 128), | ||
| (3, 2048, 2048), | ||
| (4, 3584, 640), | ||
| (13, 8704, 8576), | ||
| (26, 18944, 1664), | ||
| (67, 6656, 1408), | ||
| ] | ||
|
|
||
|
|
||
| @pytest.mark.skipif(not torch.cuda.is_available(), reason="CUDA not available") | ||
| @pytest.mark.parametrize("_, N, K", BLOCKWISE_SIZE_MNK) | ||
| @pytest.mark.parametrize( | ||
| "dtype", | ||
| [torch.float8_e4m3fn, torch.float8_e5m2] | ||
| if is_sm_at_least_89() | ||
| else [torch.float8_e5m2], | ||
| ) | ||
| def test_blockwise_quant_dequant(_, N, K, dtype): | ||
| x = torch.randn(N, K).cuda() | ||
| qx, s = fp8_blockwise_weight_quant(x, dtype=dtype) | ||
| x_reconstructed = fp8_blockwise_weight_dequant(qx, s) | ||
| error = torch.norm(x - x_reconstructed) / torch.norm(x) | ||
| print(f"Relative Error: {error.item():.6f}") | ||
|
|
||
| assert error < 0.1, "Quant-Dequant error is too high" | ||
|
|
||
|
|
||
| @pytest.mark.skipif(not torch.cuda.is_available(), reason="CUDA not available") | ||
| @pytest.mark.skipif( | ||
| version.parse(triton.__version__) < version.parse("3.3.0"), | ||
| reason="Triton version < 3.3.0, test skipped", | ||
| ) | ||
| @pytest.mark.parametrize("M, N, K", BLOCKWISE_SIZE_MNK) | ||
| @pytest.mark.parametrize( | ||
| "dtype", | ||
| [torch.float8_e4m3fn, torch.float8_e5m2] | ||
| if is_sm_at_least_89() | ||
| else [torch.float8_e5m2], | ||
| ) | ||
| def test_blockwise_fp8_gemm(M, N, K, dtype): | ||
| A = torch.randn(M, K).cuda() | ||
| B = torch.randn(N, K).cuda() | ||
| C = A @ B.T | ||
| A_q, A_s = fp8_blockwise_act_quant(A, dtype=dtype) | ||
| B_q, B_s = fp8_blockwise_weight_quant(B, dtype=dtype) | ||
| C_q = blockwise_fp8_gemm(A_q, A_s, B_q, B_s) | ||
| error = torch.norm(C - C_q) / torch.norm(C) | ||
| print(f"Relative Error: {error.item():.6f}") | ||
|
|
||
| assert error < 0.1, "Quantize gemm error is too high" |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,29 @@ | ||
| # Blockwise Quantization Implementation | ||
|
|
||
| ## Overview | ||
|
|
||
| This directory contains the implementation of blockwise quantization introduced by DeepSeek. The method involves quantizing activations and weight matrices in blocks of 128x1 and 128x128, respectively. | ||
|
|
||
| ## Quantization Process | ||
|
|
||
| ### Activation Quantization | ||
| - Activations are quantized in blocks of size 128x1 using the FP8 format | ||
|
|
||
| ### Weight Matrix Quantization | ||
| - Weights are quantized in blocks of size 128x128 using the FP8 format | ||
|
|
||
| ## Kernel Implementation in Triton | ||
|
|
||
| - The kernel for blockwise quantization is implemented using Triton | ||
| - For now, the only supported types are: torch.float8_e4m3fn and torch.float8_e5m2 | ||
|
|
||
| ## Illustration | ||
|
|
||
| 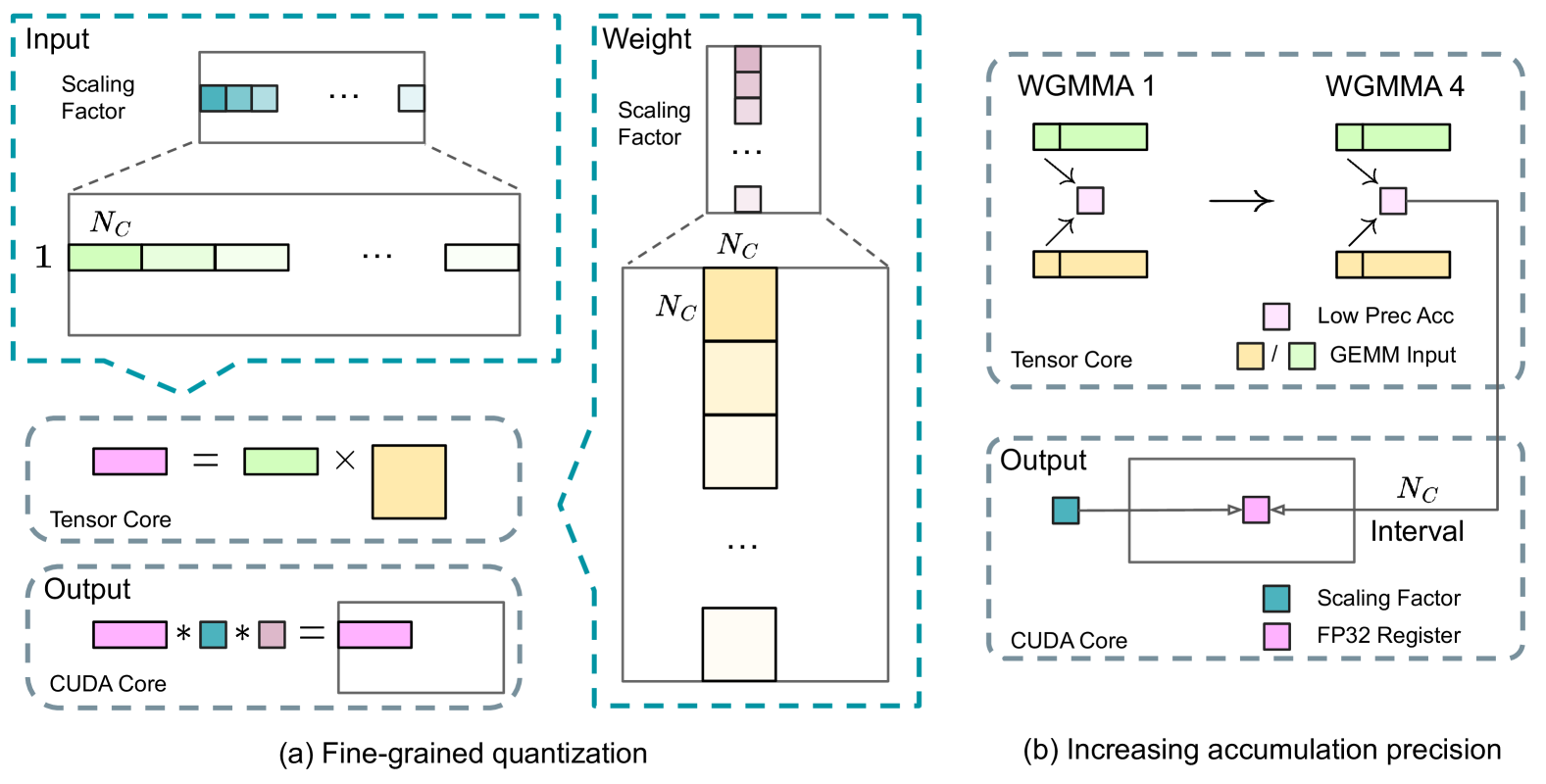 | ||
|
|
||
| *Illustration of the blockwise quantization process.* | ||
|
|
||
| ## Original Paper | ||
|
|
||
| For detailed motivations and technical specifications, please refer to the original paper: | ||
| - [DeepSeek Blockwise Quantization Paper](https://arxiv.org/html/2412.19437v1) |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,15 @@ | ||
| from .blockwise_linear import BlockwiseQuantLinear | ||
| from .blockwise_quantization import ( | ||
| blockwise_fp8_gemm, | ||
| fp8_blockwise_act_quant, | ||
| fp8_blockwise_weight_dequant, | ||
| fp8_blockwise_weight_quant, | ||
| ) | ||
|
|
||
| __all__ = [ | ||
| "blockwise_fp8_gemm", | ||
| "BlockwiseQuantLinear", | ||
| "fp8_blockwise_act_quant", | ||
| "fp8_blockwise_weight_quant", | ||
| "fp8_blockwise_weight_dequant", | ||
| ] |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,77 @@ | ||
| # Copyright (c) Meta Platforms, Inc. and affiliates. | ||
| # All rights reserved. | ||
| # | ||
| # This source code is licensed under the BSD 3-Clause license found in the | ||
| # LICENSE file in the root directory of this source tree. | ||
|
|
||
| import torch | ||
| from torch import nn | ||
|
|
||
| from torchao.prototype.blockwise_fp8.blockwise_quantization import ( | ||
| blockwise_fp8_gemm, | ||
| fp8_blockwise_act_quant, | ||
| ) | ||
|
|
||
|
|
||
| class BlockwiseQuantLinear(nn.Module): | ||
| """ | ||
| Custom linear layer with support for quantized weights and optional bias. | ||
|
|
||
| Args: | ||
| in_features (int): Number of input features. | ||
| out_features (int): Number of output features. | ||
| bias (bool): Whether to include a bias term. Defaults to False. | ||
| block_size (int): Block size for quantization. Defaults to 128. | ||
| dtype (torch.dtype): Data type for the weights. Defaults to torch.float8_e4m3fn. | ||
| """ | ||
|
|
||
| dtype = torch.bfloat16 | ||
|
|
||
| def __init__( | ||
| self, | ||
| in_features: int, | ||
| out_features: int, | ||
| bias: bool = False, | ||
| block_size: int = 128, | ||
| dtype: torch.dtype = torch.float8_e4m3fn, | ||
| ): | ||
| super().__init__() | ||
| supported_dtypes = [ | ||
| torch.float8_e4m3fn, | ||
| torch.float8_e5m2, | ||
| ] | ||
| assert dtype in supported_dtypes, ( | ||
| f"Unsupported dtype: {dtype}. Supported dtypes: {supported_dtypes}" | ||
| ) | ||
| scale_in_features = (in_features + block_size - 1) // block_size | ||
| scale_out_features = (out_features + block_size - 1) // block_size | ||
| self.weight = nn.Parameter(torch.empty(out_features, in_features, dtype=dtype)) | ||
| self.weight.scale = self.scale = nn.Parameter( | ||
| torch.empty(scale_out_features, scale_in_features, dtype=torch.float32) | ||
| ) | ||
| self.block_size = block_size | ||
| self.dtype | ||
|
|
||
| if bias: | ||
| self.bias = nn.Parameter(torch.empty(out_features)) | ||
| else: | ||
| self.register_parameter("bias", None) | ||
|
|
||
| def forward(self, x: torch.Tensor) -> torch.Tensor: | ||
| """ | ||
| Forward pass for the custom linear layer. | ||
|
|
||
| Args: | ||
| x (torch.Tensor): Input tensor. | ||
|
|
||
| Returns: | ||
| torch.Tensor: Transformed tensor after linear computation. | ||
| """ | ||
| x, scale = fp8_blockwise_act_quant(x, self.block_size, self.dtype) | ||
| y = blockwise_fp8_gemm( | ||
| x, scale, self.weight, self.weight.scale, self.block_size | ||
| ) | ||
|
|
||
| if self.bias is not None: | ||
| y += self.bias | ||
| return y |
Oops, something went wrong.
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.