2021年12月12日,我在 Mammoth Mountain 滑雪,气温在零下10到15度之间,中午前风力极大,缆车摇晃到45度,能见度很差,雪道冰硬。我原本计划挑战 Chair 23 的 Dropout Chute 和 Wipeout Chute。早上先在 Gravy Chute 滑了两趟热身,状态极佳,决定不再使用 jump turn,直接滑下。
起初一切顺利,几次转弯都很流畅,心里甚至想着:这双黑道也不过如此。正得意时,突然一个转弯幅度过大,瞬间失去平衡,整个人头朝下开始翻滚。42度的坡度和重力让我完全无法控制速度,向山脚高速翻滚,整整滚了约200米才神奇地停下来。检查后发现只掉了一块雪板,心想算是幸运,打算继续滑下去,但第一个弯就发现左膝完全无法发力,像是失去了知觉,再次摔倒又滚了约100米。这时明显感觉腿无法伸直,勉强可以走几步但疼痛明显。路人见状叫来了救援,我被雪橇送下山。随身物品几乎都在,只有运动相机永远留在了雪山一角。
⸻
受伤初期(2021/12 - 2022/1)
X光显示胫骨平台有撕脱性骨折,医生怀疑ACL断裂。后续MRI证实最坏的结果:ACL完全断裂,半月板复杂撕裂,还有提篮样碎片移位卡住关节。这通常意味着剧烈运动要告别了。那时腿无法伸直,日常全靠拐杖,出门极其不便,尤其痛恨家里的浴缸设计——对于行动不便者非常不友好。
1月初去看主刀医生时,膝盖只能弯90度且无法伸直。他建议“两期手术”:先恢复活动度并修复半月板,几个月后再重建ACL。我直接决定尽快动手术,虽然许多人会去多问几个医生,但我当时内心相信这位医生的判断。
⸻
第一次手术:半月板修复
术前医生估计半月板可能需要切除。麻醉前,我问了最后一个问题:“我还能滑雪吗?”医生回答:“Absolutely you can.” 睡醒后护士告诉我:“有个好消息,医生成功修复了半月板!”这是远低于50%概率的好消息。手术报告显示半月板缝了七针,软骨保存情况良好。
⸻
手术初期恢复(2022/1 - 2022/3)
半月板修复恢复期长,术后一个月内几乎不能负重。我采取极其保守的恢复策略:长时间抬腿冰敷、肌肉收缩训练(如股四头肌等),初期不能做直腿抬高练习以避免髌骨损伤。前三周膝盖弯曲角度不能超90度,只能练习脚踝活动和股四头肌收缩,同时逐步恢复弯腿活动度。每天冰敷数次,下床需戴好ACL支具。
我每周安排两次复健,复健师非常专业,首节课就帮我提升了膝盖弯曲角度10度。术后第三周,我逐渐尝试双脚负重站立。到了2月初,已经可以坐在桌前较长时间,走路时使用单拐。2月底,正式脱拐!
⸻
手术中期恢复(2022/3 - 2022/5)
脱拐后重心转为力量训练,尤其是股四头肌。我从椅子辅助半蹲开始,逐渐加入直腿抬高、侧抬腿、平板支撑等。复健中,我做平板撑3分钟被提醒“够了”,转而尝试 dead bug、side plank 等高效动作。尽管走路时膝盖偶有不稳感,主要原因是ACL仍然断裂,左右腿力量差距巨大——左腿只能负重40磅,右腿约200磅。
⸻
第二次手术:ACL重建(2022/5)
4月底检查确认可以手术,医生建议使用BTB(髌腱)移植物进行ACL重建。手术顺利完成,醒来后甚至和协作者讨论起科研话题。医生术后打来电话,确认半月板愈合良好,这是受伤以来最好的消息。由于采用了分期手术方案,恢复负重速度更快。
⸻
ACL术后初期恢复(2022/5 - 2022/7)
术后肿胀明显,疼痛强于第一次手术,但第三天就明显缓解。第六天开始复健,膝盖弯曲到105度。我持续以保守策略进行锻炼,重点加强股四头肌与小腿肌群,开始骑动感单车,逐渐增加单腿练习强度。术后六周,膝盖活动度回到130度。
⸻
中期恢复(2022/7 - 2022/10)
恢复正常走路花了很久,直到10月底才走得像正常人。复健师指出我左腿走路姿势僵硬,并制定了分阶段练习计划(抬腿、轻弯着地、蹬地)。后续发现左臀紧张是问题根源,练习放松臀部后改善显著。
9月搬到西雅图后,换了更偏向“运动能力”的复健中心,项目多且强度大。此时我已能进行登山等运动。但仍存在膝盖弯曲不足的问题,复健师用“拔火罐疗法”试图松解粘连,效果略有改善。
⸻
突发状况(2022/10/18)
一次散步下坡时膝盖“啪”地一声,瞬间变得异常灵活,像失去了拉力,我极度恐慌是否是ACL断裂。复健师检查认为稳定,医生也表示无碍,MRI后确认韧带完好,可能是粘连组织被松解,反而带来了积极变化。通过恢复期静养和走路姿态调整,弹响明显减少,活动度提升。
⸻
后期恢复与回归(2022/12 - 现在)
之后恢复平稳,逐步开始跳跃训练,先双脚跳再到单脚跳。2023年3月开始跑步训练,发现左腿负重仍然不足,进一步强化训练后情况明显改善。我还引入了硬拉和核心训练,加强腘绳肌与核心肌群。
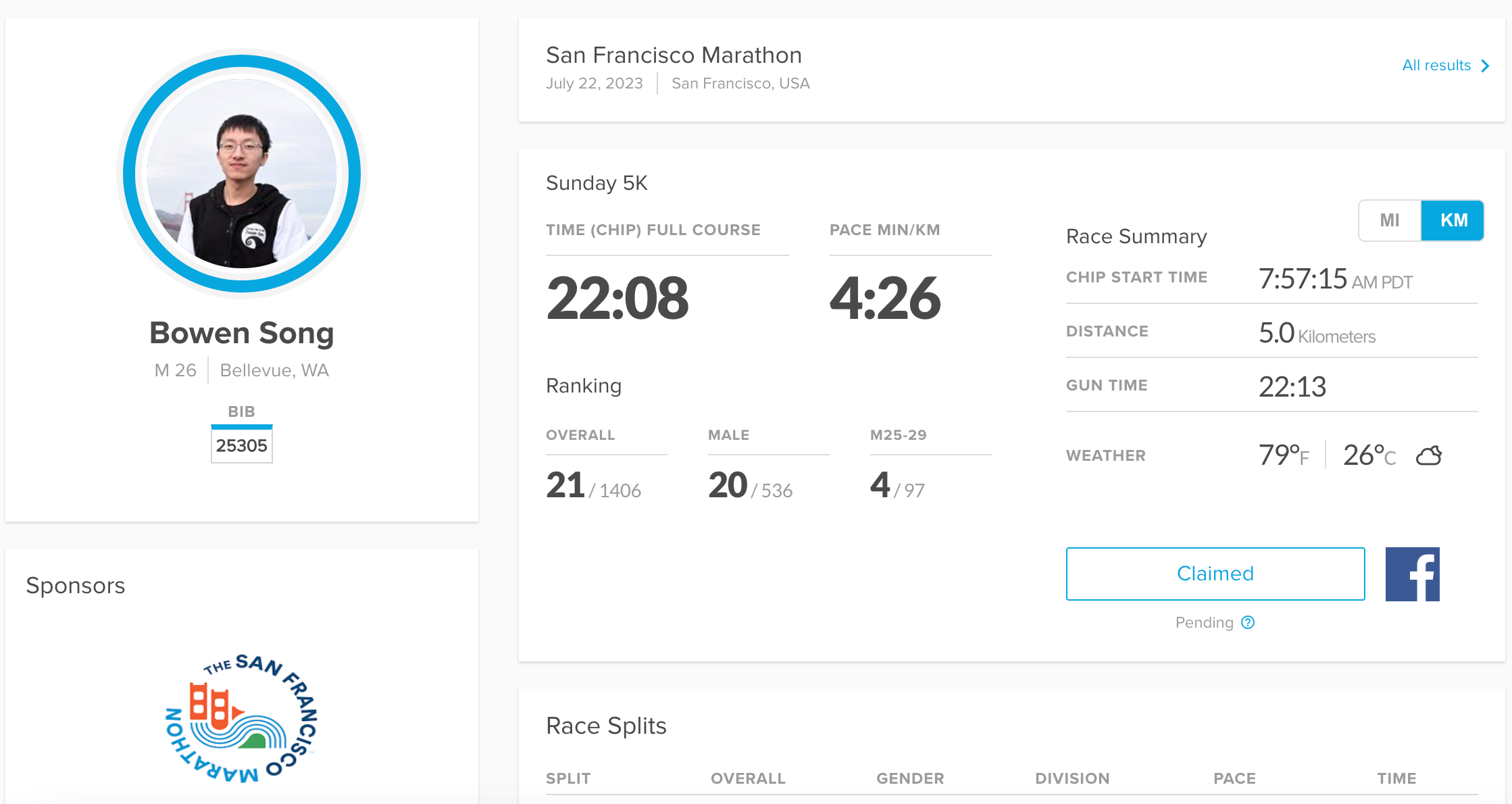
2023年6月起正式开展系统跑步训练,采用间歇+轻松跑结合策略。研究表明跑得快反而对膝盖冲击更小,因此我坚持高速度短时间的训练法。7月23日,我顺利完成了旧金山马拉松的5K比赛,总排名21,年龄组排名第4,且赛后膝盖完全无不适。可以说,已经从ACL伤病中“毕业”,尽管仍有不足,但我会继续努力、不断进步。
⸻ 2025/4/21 5K 比赛中跑出19:19, 向sub-18努力