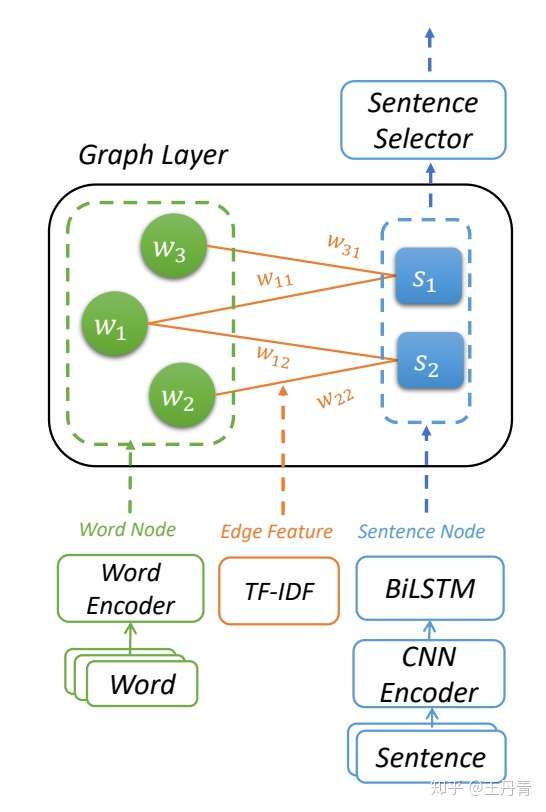
Danqing Wang, Jiaze Chen, Hao Zhou, Xipeng Qiu†, Lei Li
ACL 2021 Findings
论文:https://aclanthology.org/2021.findings-acl.242.pdf
代码:https://github.com/brxx122/CALMS
网页:https://dqwang122.github.io/projects/CALMS/
AI科技评论:https://mp.weixin.qq.com/s/DDbpUKiOo1sT6q01deWI3w
引言
在快节奏的生活中,人们往往没有耐心阅读长篇大论,而是希望能够通过简短的文字迅速掌握文章的重点信息,从而判断是否有必要详细阅读。因此不管是在新闻推送还是在论文撰写,为文章提取一个简明扼要的摘要都是十分重要的。以往这项工作都是由文章作者或者专门的编辑进行,而现在,人们可以通过 AI 模型自动为文章提供摘要,大大解救了为总结全文而绞尽脑汁的作者编辑们。
紧随国际化的步伐,我们对于摘要生成的需求也不再局限于单种语言。对于我们熟悉的中文,阅读摘要自然能够节约部分时间,但是对于不熟悉的英法德等语言,我们更需要通过摘要来判断是否有必要花费大量精力对全文进行翻译阅读。然而,为每一种不熟悉的语言建立一个模型实在是过于繁重,我们最希望的是有一个统一的模型,能够同时对多种语言的文章进行阅读理解,同时生成对应语言的摘要输出,这就是多语言摘要的研究核心。
一个优秀的模型除了精心的算法设计,还离不开大量的数据。由于摘要本身撰写难度,人们很难收集到大量高质量的文章-摘要对数据,这个现象在小众的语言上尤为突出。因此,要解决多语言摘要问题,我们首先需要解决的是数据问题。有了数据之后,我们希望能够让模型取长补短,利用资源丰富的语言数据来扶贫资源稀缺的语言。
这里为大家介绍一篇来自 ACL2021 Findings 的多语言摘要工作《Contrastive Aligned Joint Learning for Multilingual Summarization》。
该篇文章由字节跳动人工智能实验室和复旦大学合作完成,主要提供了一个囊括了12种语言,总数据量达到100万的新多语言数据集 MLGSum。同时,该篇工作设计了两个任务来提取文章信息并在多种语言间进行语义对齐,从而来同时提升模型在多种语言上的摘要性能。

多语言摘要数据集 MLGSum
机器学习模型,算法为主,但数据先行。没有高质量的大规模数据只能是巧妇难为无米之炊。然而,目前绝大多数摘要数据集均集中在英文上,最近提出的多语言数据集MLSUM[1]也只提供了5种语言。
因此,作者首先从多语言新闻网站上收集了大量的新闻数据并进行筛选,保留包含人工摘要的部分数据,最终获得了包括 12 种语言,总共文章-摘要对高达100万的大规模数据集。具体语言和数据分布见图 1,其中纵坐标单位为万。
通过柱状图可以看到,德语(De),英语(En),俄罗斯语(Ru),法语(Fr)和中文(Zh)的数据量较多,其余几种语言的数据量较少。因而作者以此为划分,前面5种作为高资源语种,后面7种作为低资源语种。
作者的目标在于,在高资源语种上训练一个联合模型,使得其能够同时在5种语言上获得优于单语言模型的性能。与此同时,该联合模型能够很好地迁移到低资源语种上。

对比学习的多语言摘要模型 CALMS
针对摘要的任务特性,作者利用对比学习的思想,设计了两个句子级别的辅助任务。
第一个叫 对比句子排序(Contrastive Sentence Ranking, CSR),其目的是帮助模型分辨出哪些信息更加重要。
具体做法是,首先从文章中随机抽取出若干个句子作为摘要候选;其次将这些候选项和标准摘要进行对比,相似度最高的作为正样本,其余作为负样本。在模型学习过程中,需要将正负样本的表示距离不断拉大,从而分辨出文章中哪些句子对摘要更加重要。
第二个叫 对齐句替换 (Sentence Aligned Substitution, SAS),其目的是拉近不同语言间相似句子的距离。
具体来说,首先作者从语言A的文章中抽取出一些重要信息句(如前几句),翻译成另一种语言B并且进行替换,模型需要根据替换后的混合文章将原始句子还原出来。这个任务希望能够借助翻译拉近语种间的语义表示。从一方面来说,还原的过程可以认为是对重要信息句做B到A的翻译;从另一个方面来说,可以将其视作利用A文章的剩余内容来还原重要信息句。基于重要信息句的信息量和剩余所有内容的信息量之和相似的假设,可以将这个过程视作自监督摘要。

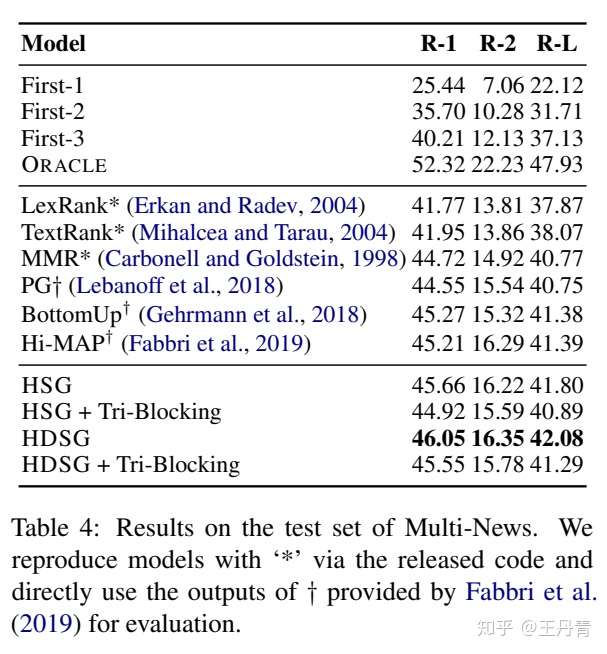
性能一览
作者利用 mBART 模型[2]作为多语言语言模型初始化,并且利用上述两个任务进行进一步微调,最终获得了模型CALMS(Contrastive Aligned Joint Learning for Multilingual Summarization)。
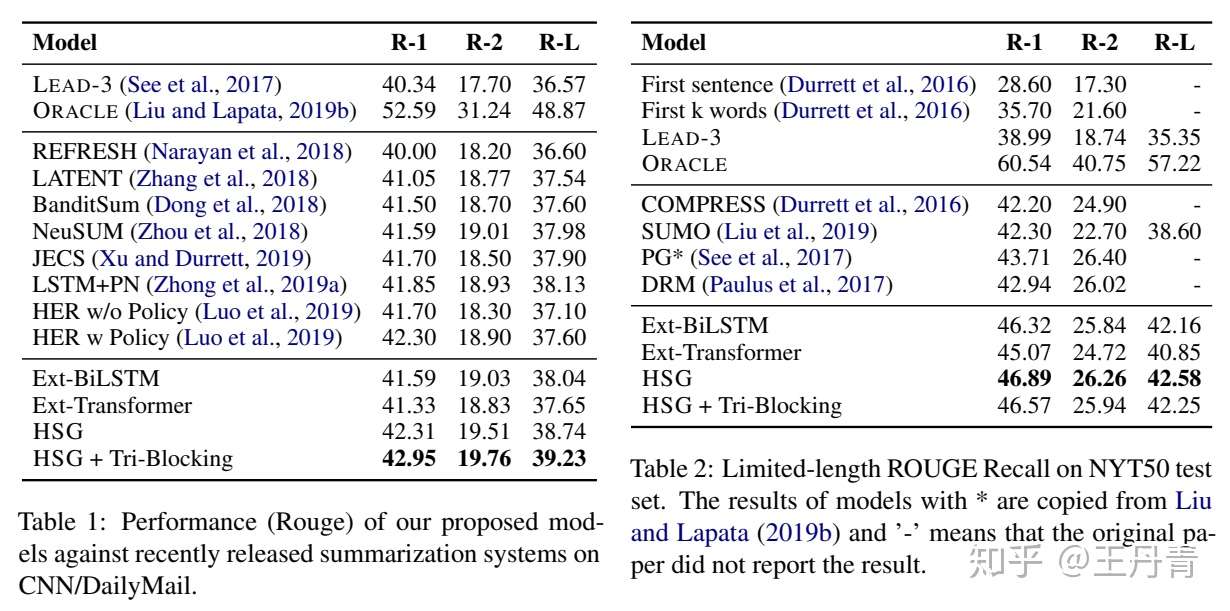
首先在5种高资源语言上进行了实验,结果如下所示。其中Mono模型为每种语言一个的单语言模型,Multi模型为联合的多语言模型。可以看出,通过上述两个方法的设计,联合模型在每种语言上都优于单语言模型,并且通过针对每种语言的微调可以进一步提升性能。

此外,针对低资源语言,作者将上述在5种语言上联合训练的模型 CALMS 作为初始化,迁移到低资源语言上。其中 Transformer 和 mBART 为直接在该低资源语言上训练的模型。
可以看到,针对上述5种语言较为相近的几个语系,如Romance罗曼语(Fr Pt Es 法语 葡萄牙语 西班牙语)和Savic斯拉夫语(Ru Uk 俄语 乌克兰语),CALMS明显优于直接训练的单语言模型,但是对于较远的几个语系,效果有所下降。这是因为CALMS针对上述5个语种进行针对性微调优化,导致语义空间和其余语系更远。同时针对没有被mBART覆盖的Id印度尼西亚语,CALMS取得了优于单语言模型的效果,这是因为CALMS对摘要任务本身提取重要信息的能力也进行了加强。

总结
该篇文章为了解决多语言摘要问题,首先提出了一个包含 12 种语言的摘要数据集 MLGSum;其次针对多语言和摘要两个特性设计了两个辅助任务,来加强模型提取重要信息和语言间对齐的能力。最终联合模型CALMS在5种高资源语言上取得了优于单语言模型的能力,并且证实了其在相似语系中有着良好的迁移能力。
参考文献
[1]Thomas Scialom, Paul-Alexis Dray, Sylvain Lamprier, Benjamin Piwowarski, and Jacopo Staiano. 2020. Mlsum: The multilingual summarization corpus. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8051–8067.
[2] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics, 8:726–742.