-
-

-

-

legend
-

-






Inspiration
Traditional Thesauruses' Result
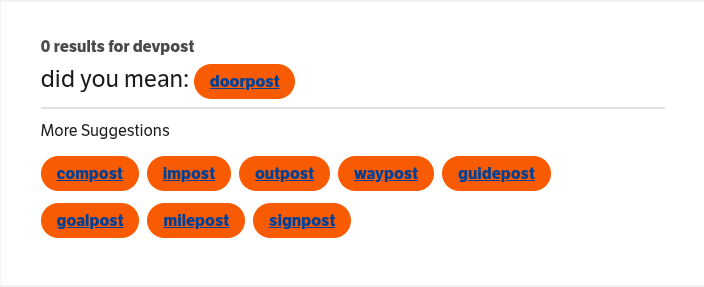
Our Thaisaurus' Result

We were inspired by our collective frustration on how thesaurus websites are much too rigid with their inputs and outputs.
Our solution enables users to query for synonyms and antonyms to whole concepts they describe in detail, instead of simply a single word.
This is exactly the kind of tool we have always wanted, and when it is open source, self-hostable, and bundled with a beautiful UI, it has proven to be an immensely powerful tool.
What it does
Thaisaurus is the next generation of what an idealized thesaurus should be. Thaisaurus lets you enter in a word or phrase, and will find similar feeling words (sort of like a thesaurus' synonyms) and also opposite feeling words (antonyms). You can just as easily find synonyms for the word "iridescent" as you can find "how it feels to play minecraft".
First, it generates "embeddings" from user prompts. What this means is that it takes the user's input and a model does as best it can to convert all the context and information in that natural language into numbers, into a vector. Then this vector of numbers is used to query a vector database of accepted words and phrases to find the concepts most closely synonymous and antonymous with the user prompt.
How we built it
Front-End:
The frontend is built with Vite+React (w/ Typescript using the new React Compiler!). We used Tailwind for styling, AriaKit for our popovers, and motion.dev for the animations.
Back-End:
We wrote the api for resolving user queries in Python using the FastAPI library.
All data is stored in a Qdrant vector database, that the api communicates with.
Deployment:
The application is built into Docker containers and hosted using Docker on a VPS. The VPS is running NixOS, infrastructure as code. We build these Docker images on GitHub actions. All the relevant services are behind a Caddy reverse proxy written in Docker Compose.
Challenges we ran into
Front-End:
The largest challenge by far for the front-end was rendering all of the nodes.
Our first attempt involved rendering an extra large element that would serve as the container for all of the nodes, and translating it when the user clicks and drags the background. This worked for desktop environments (albiet, finicky), but failed to accomodate for native scrolling behavior on devices using trackpads and mobile devices. Most importantly, when the user changes their zoom level, all of the functionality on the app breaks -- all of the nodes would get displaced, and the bounds of the graph would not correctly restrict panning.
Ultimately, our working solution still involved the extra large div, but we relied on native browser scrolling instead of a translate method.
It works by simply hiding the scroll bars and then centering the user into the center of this huge container. Then, to add dragging support the code from the previous attempt was upcycled to allow that to happen, but specifically filtering for mouse pointer devices so that it would allow mobile users to pan around. There was also the challenge of specifically Mac trackpads, which for some reason in most scroll containers force constrain you to scroll only in one direction. This was solved with a little piece of code which accounts for this extraneous constraining on the actual scrolling and "reimburses" it as such. In practice, you notice nothing wrong.
Back-End:
A major challenge was discovering the optimal strategy for storing and querying concepts.
The first thing we tried was embedding the single words on their own and uploading those embeddings to the database. Then requesting a simple nearest vector query by the cosine distance model on the database. The results seemed promising, but we quickly realized an issue. This kind of search was a purely "semantic" search. This means that it finds concepts that are semantically similar, but not necessarily synonyms or antonyms, like how a thesaurus should behave. For example, a query for "hot" would result that "cold" was one of the closest 'synonyms.' This is obviously incorrect, as they are direct antonyms, but since they are so close 'semantically,' this was the behavior of the database. What it means to be semantically similar is that they exist in the same contexts, so this behavior is actually perfectly ordinary and correct, the problem was simply our approach.
Our next step was diving into
We grew to be intimately familiar with the behavior and usage of embedding and instruction models. Especially concerning embedding vector generation and working with them in a vector database. We also learned how to use several powerful tools for working with natural language, such at NLTK and SentenceTransformers in python.
What's next for Thaisaurus
The next step is allowing users to input their own definitions into the database. Right now when a user queries a prompt that is not yet stored in the database, it goes through a large language model to describe the meaning of their query and then through an embedding model to generate the vector. From here it would be easy to upload this "new" definition into the database, but we refrain from doing this for now due to user usage concerns. We would need to implement guardrails to stop malicious or reckless activity.research in the field. Reading papers and discussions by researchers and experts gave many insights into how these embedding models work. The next strategy we tried was using a large group of synonymous words and finding their average to derive a "concept centroid" axis. The idea was that we would be able to add this "synonym" vector to any embedding and land directly in the middle of the synonym group in the vector space, so our simple nearest neighbor vector query would return strong synonyms. Similarly for antonyms, taking a large list of synonym-antonym pairs and subtracting the antonym embedding vector from the synonym embedding vector for each of them, then taking the average of those delta vectors would hopefully construct an "opposition axis vector" that we would be able to add to any vector embedding to land in the antonym space. While the papers were interesting and introduced many seemingly ingenious strategies, these methods were unfortunately not fruitful with the modern embedding we were testing with.
The problem was that these papers were written for ancient models with very linear vector spaces and they were trained to learn by contrast. This enabled the special behavior that those papers cleverly leveraged, but this kind of vector structure is not present in modern embedding models that are trained to be highly context-aware.
Accomplishments that we're proud of
Front-End:
The thing that we aimed to accomplish with the frontend was a clean design that would keep the user's attention, while simultaneously trying not to overwhelm the user. Our usage of motion.dev allowed us to render unique spring animations that give the animations life, and also, allows us to omit animations where they would bog the user down. For example, in the the part of speech filter in the input, there is no animation, simply because users who rely on the visual display would want it faster, and experienced users might not even look at all.
A fun thing we cooked up for the display is the positioning and color of the points. Since our thesaurus works by rendering a graph and the user can pan through the graph, each synonym and antonym is represented by a point on this graph. We decided to calculate the positions and colors as functions of the similarity to the desired synonym/antonym concept. This function computes the points to form a sort-of vortex shape coming out of the user query node. The color also interpolates from green/red to white depending on how close it is to the target synonym/antonym concept vector.
$$ p(s)=\left(50,50\right)+\left(13\sqrt{1-s}+10\right)\left(\cos\theta,-\sin\theta\right)\operatorname{with}\theta=\left[\frac{\pi}{6},\frac{\pi}{6}+\frac{\left(\frac{5\pi}{6}-\frac{\pi}{6}\right)}{n-1},...,\frac{5\pi}{6}\right]-\frac{1.5\pi}{6} $$
Back-End:
Eventually we landed on utilizing the modern models for what they are best at: generating with context. Instead of embedding single words, we found that embedding the definition of the word into a vector, then querying with a description of the concept, resulted is very strong synonym and antonym resolution. This was exactly the behavior we were searching for, and it was a great success.
The results weren't perfect yet -- after tuning the results with filters like the part of speech and sentimentality, then trimming the results to not include words with the same root more than once, the results become quite close to a proper thesaurus.
Deployment:
Our solution is clean, and lets us iterate quickly. We can easily add changes to our code and rapidly build and deploy which is really nice during this period of rapid development, especially as all the services were coming together. It also eased some of the effort on our backend since it allowed any data we began to synthesize to be uploaded to the production hardware, to be ready for the final deployment.
What we learned
Front-End:
Over the course of this project, we learned that the best solution was the easiest solution. Initially, our panning solution was overly complex, but we failed to think about what was already implemented for us---native scrolling behavior. This isn't to say that there was nothing valuable in our initial idea, but sometimes, when you are caught up in the moment, it becomes easy to go crazy with ideas, when really, the answer was in front of you all along.
Back-End:
We grew to be intimately familiar with the behavior and usage of embedding and instruction models. Especially concerning embedding vector generation and working with them in a vector database. We also learned how to use several powerful tools for working with natural language, such at NLTK and SentenceTransformers in python.
Built With
- asyncio
- embedding-model
- fastapi
- httpx
- nix
- nltk
- python
- qdrant
- react
- tailwindcss
- typescript
- uvicorn
- vector-database
- wordnet

Log in or sign up for Devpost to join the conversation.