

Software project failure is often misunderstood. When projects go off the rails, the first instinct is to look for a person to blame – the architect who made a bad call, the PM who let scope creep in, the team lead who did not escalate early enough. Stakeholders assume that better engineers, more experienced developers, or a different team lead would have produced a different outcome. That instinct is almost always wrong.
In reality, many failing projects are built by highly capable, experienced teams – engineers who have delivered complex systems before, understand best practices, and are fully committed to success. The real culprits are structural. They are the invisible scaffolding, or the lack of it, that determines whether even the best individual contributors can coordinate effectively.
Process gaps, governance failures, communication breakdowns, and misaligned incentives do not announce themselves loudly. They accumulate quietly across dozens of small daily decisions until the damage becomes too large to ignore. Strong teams cannot compensate for broken systems. They slow down, grow frustrated, and eventually deliver something far short of what everyone intended – not because they lacked skill, but because the environment they were working in made success structurally unlikely.
This distinction matters enormously for any organization that invests in software development. If you treat project failures as a people problem, you will keep hiring different people and getting similar results. If you recognize them as structural problems, you can diagnose the actual failure modes, fix the underlying conditions, and build an environment where good teams can genuinely perform.
In this post, we will discuss the most common structural reasons software projects fail – including process gaps, governance breakdowns, communication failures, and scaling traps – and what organizations can do to address them before they become the kind of failure that ends projects and drains budgets.
- The Myth of "If the Team Is Good, the Project Will Succeed"
- Process Gaps: Where Execution Starts to Break Down
- Symptoms, Root Causes, and Structural Fixes
- Governance Failures: When No One Is Really in Control
- Communication Failures: The Silent Project Killer
- The Hidden Role of the Discovery Phase
- Scaling Problems: When Growth Breaks the System
- The Cost of Finding Problems Too Late
- How to Build a System Where Good Teams Actually Succeed
- How Developex Approaches Structural Delivery Risk
- Conclusion
The Myth of “If the Team Is Good, the Project Will Succeed”
It is tempting to believe that hiring a strong engineering team is enough to guarantee delivery. Talent is visible, measurable, and easier to evaluate than processes or governance structures. This belief creates a dangerous oversimplification – one that leads organizations to invest in personnel while neglecting the systems those people depend on.
Software delivery is not just a function of individual performance. It is a system. That system includes planning, communication, decision-making, prioritization, and risk management. When any of these elements are weak, they introduce friction that no amount of engineering excellence can fully overcome. A high-performing team inside a poorly structured environment will spend more time clarifying requirements than building solutions. They will revisit decisions, rework features, and navigate conflicting priorities. Productivity decreases, frustration increases, and delivery becomes unpredictable.
Consider what happens on a team with no formal escalation path. A developer identifies a critical risk – a third-party API that will not support the required throughput at scale – but has no clear channel to raise it to the project lead or the client. They mention it in a standup, it gets noted and forgotten, and three months later the limitation becomes a hard blocker two weeks before launch. Was this a communication failure? Technically, yes. But the real failure was that no structure existed for capturing and acting on technical risk. A proper risk log and escalation protocol would have caught this in week two. One person behaving slightly differently would not have.
This reframe is not about removing accountability from individuals. It is about placing accountability at the right level. Senior leaders and engineering managers are accountable for the structural conditions their teams operate in. When those conditions are poor, even highly capable people will underperform. When they are well designed, teams consistently deliver above expectations.
This is one of the most consistent findings across decades of software engineering research – according to the DORA State of DevOps Report, organizational structure and delivery practices predict software outcomes more reliably than individual talent alone. A great team inside a broken system will consistently underperform.
Process Gaps: Where Execution Starts to Break Down
Process gaps rarely appear as obvious failures. They emerge as small inconsistencies that gradually reduce clarity and predictability. Teams continue working, features are delivered, and milestones appear to be met – but the underlying misalignment grows. Without clear processes, teams are not aligned on what needs to be built, why it matters, or how success is measured. The result is rework, inefficiencies, and missed expectations. Here are the gaps that cause the most damage:
- No structured discovery or planning phase. Teams that move directly into development skip the step where requirements are pressure-tested, dependencies are mapped, and risks are identified. This creates an illusion of speed. In reality, teams are deferring risk – and it surfaces later at a much higher cost.
- Vague or evolving requirements without validation. When requirements are assumed rather than confirmed, different team members build to different mental models. Features technically meet specifications but fail to deliver business value, and the gap only becomes visible at demo or launch.
- Missing estimation frameworks or unrealistic timelines. When estimates are produced casually, without reference to historical data or risk buffers, schedules become fiction. Teams begin to over-promise and under-deliver as a structural norm rather than an exception.
- No clear backlog prioritization or ownership. A backlog without a clear owner and a defined prioritization method becomes a wish list. Teams pull work in inconsistent directions and lose the alignment needed to deliver coherent product increments.
- Weak QA processes or late-stage testing. QA treated as a final gate rather than a continuous activity consistently produces late-stage bug surges. By the time issues are found, the cost to fix them is an order of magnitude higher than it would have been earlier in the cycle.
- No feedback loops during development. Short feedback loops – sprint demos, continuous integration, embedded QA – catch problems early. Without them, misalignments compound for weeks before anyone notices. Teams that invest in feedback loops move faster over the life of a project, not slower.
Teams don’t fail because they move too slowly. They fail because they move without alignment.
Symptoms, Root Causes, and Structural Fixes
One of the most useful exercises for any engineering leader or project sponsor is mapping observable project symptoms to their structural root causes. The surface symptom – a slipping deadline, a late-stage bug surge, a frustrated stakeholder – is rarely the real problem. It is a signal pointing to something broken in the underlying process, governance, or communication structure. The table below maps the most common symptoms to their structural origins and the fixes that address them at the root.
| Symptom | Root Cause | Structural Fix |
| Deadlines keep slipping | No buffer in sprint planning; estimates made without risk assessment | Introduce formal estimation reviews and realistic capacity planning |
| Requirements change mid-sprint | Stakeholders not aligned at discovery; no change control process | Establish a change request workflow with impact assessment sign-off |
| Bugs found late in QA | QA treated as a final gate rather than a continuous activity | Shift QA left – embed testers in sprints and require unit test coverage gates |
| Teams duplicating work | No shared visibility into task status; unclear ownership boundaries | Mandate daily standups with a blockers board and RACI for all workstreams |
| Architecture decisions revisited repeatedly | No architectural decision records; institutional memory lives in individuals | Implement ADR process; key decisions documented and reviewed by leads |
| Stakeholder dissatisfaction despite delivery | Success criteria undefined at project start; delivery measured by output not outcomes | Define measurable acceptance criteria before development begins |
| High developer turnover mid-project | Unclear progression, poor feedback culture, or overwork without recognition | Regular one-on-ones, structured retrospectives, and workload monitoring |
| Integration failures near launch | Teams built in silos; integration tested only at the end | Require integration testing from sprint 2 onward with a shared environment |
Governance Failures: When No One Is Really in Control
Governance is often misunderstood as bureaucracy. In reality, it is the mechanism that enables clarity and speed in decision-making. It is the set of structures that ensure the right people are making the right decisions at the right time – and that those decisions actually get implemented. A project can be very well managed at the team level and still fail at the governance level, because governance operates across teams, across organizational boundaries, and at a longer time horizon than sprint planning.

The most common governance failure is the absence of a clear decision-making authority. On many projects, it is genuinely unclear who has final say on product direction, technical architecture, resource allocation, or scope changes. Decisions get made by whoever is most available, most persistent, or most senior in the room – not necessarily the person with the best information or the appropriate accountability. The result is a project that changes direction frequently, revisits settled questions, and struggles to maintain momentum because nobody fully trusts that today’s decision will hold tomorrow.
Closely related is the problem of misaligned success metrics. When the engineering team is measured on story points delivered, the product team on features shipped, and the business on revenue impact, each group optimizes for a different outcome. The project can hit all of its internal metrics and still fail to deliver meaningful value – because no one ever aligned on a shared definition of success. Effective governance starts with a shared understanding of what winning looks like, expressed in terms all stakeholders can agree to and that can be measured objectively at project completion.
Vendor and partner governance is another common failure point. When an external development team is involved, the contract typically covers deliverables, timelines, and payment terms. What it rarely covers with sufficient precision is the decision-making interface between the client and the vendor – how architectural decisions get reviewed, how change requests are evaluated, how quality gates are enforced, and how escalation works when things go wrong.
Without this structure, the relationship devolves into informal communication patterns that work fine when everything is going well and collapse under pressure. Strong governance does not require heavy overhead. It requires three things: clarity on who decides what, a cadence of structured checkpoints where those decisions are made with the right information, and a documented record that prevents decisions from being relitigated repeatedly.
Communication Failures: The Silent Project Killer
Of all the structural failure modes in software delivery, communication breakdowns are both the most common and the most underestimated. They are underestimated because they rarely appear on project dashboards. No ticket is opened for “engineering and product are operating with fundamentally different assumptions about the API.” No alert fires when a key stakeholder has not been updated on a scope change for three weeks. These failures are invisible until their consequences become very visible. Most project failures are not technical failures – they are communication failures with technical consequences. The patterns below are the most reliably damaging:
- Assumptions treated as agreements. In fast-moving teams, people frequently make assumptions about how a feature will work, what a deadline means, or what a handoff requires – and proceed as if those assumptions have been confirmed. Without explicit written confirmation of key agreements, teams regularly discover late in the project that they were building from different mental models.
- Siloed team communication. When development, QA, design, and product each communicate primarily within their own lane and only surface issues at formal review points, problems that span those lanes go undetected for too long. Cross-functional communication – even brief daily check-ins – dramatically reduces integration surprises.
- Status reporting that obscures reality. Teams under pressure develop a tendency to report green when things are amber, and amber when things are red. This is rarely dishonest – it usually reflects optimism or a belief the problem will resolve itself. The effect is that leadership loses accurate visibility into project health until it is too late to intervene.
- No defined channel for bad news. If the culture makes it uncomfortable or risky to raise concerns, concerns stop being raised formally. They circulate informally – in Slack DMs, in hallway conversations – but never reach the people who could actually act on them.
- Stakeholder communication managed ad hoc. When client or executive updates happen reactively rather than on a defined cadence, stakeholders fill the information vacuum with their own assumptions and concerns. Regular structured updates – even short ones – maintain trust and alignment far more effectively than crisis communications when things go wrong.
- Technical decisions not communicated to business stakeholders. Many project failures involve a moment where a significant technical decision – a platform change, an architecture compromise, a scope reduction to meet a deadline – was made without the business fully understanding its implications. Bridging this gap requires deliberate effort, not just technical documentation.
The Hidden Role of the Discovery Phase
One of the most critical – and most frequently skipped – stages of a software project is discovery. It is skipped because it feels like a delay. Stakeholders want to see progress, and progress is assumed to mean code being written. So teams move directly into development, believing they are accelerating delivery. In reality, they are deferring risk. The problems that a proper discovery phase would have surfaced in days will surface instead in month three, when the cost of addressing them is five to ten times higher.
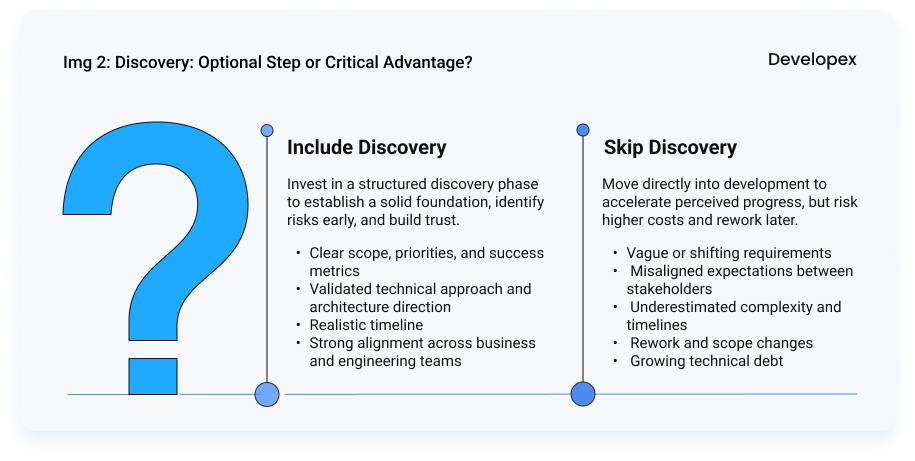
A proper discovery phase is not a prolonged requirements-gathering exercise. Done well, it is a focused, time-boxed effort – typically one to three weeks – that establishes the foundation every subsequent decision depends on. It starts with a clear definition of business goals and measurable success criteria, so the team knows not just what to build but what winning looks like. It validates technical feasibility before architecture decisions are locked in. It identifies risks, constraints, and dependencies that are invisible on a feature list but will absolutely affect delivery. It produces high-level architecture decisions that the whole team can align around. And it establishes shared agreement on scope, priorities, and timelines, typically captured in a project requirements document – not the optimistic version, but the realistic one that accounts for what the team has learned during discovery itself.
The most common objection to a structured discovery phase is that it slows things down. The data consistently says the opposite. Teams that invest in discovery ship faster overall, because they spend less time on rework, fewer sprints revisiting requirements that were misunderstood, and less energy navigating the organizational friction that builds up when stakeholders discover late that the product being built is not the product they envisioned. Skipping discovery does not eliminate that cost – it defers it and amplifies it. A week of structured discovery at the start of a project routinely prevents a month of rework in the middle of one.
There is also a relationship dimension that is easy to undervalue. Discovery is the moment when a development team and a client or product stakeholder first have to work through ambiguity together. Done well, it builds the mutual trust and shared vocabulary that makes every difficult conversation in the months ahead easier to navigate. Done poorly – or skipped entirely – it means that trust has to be built under pressure, in the middle of delivery, when stakes are higher and patience is shorter. The discovery phase is not overhead. It is the investment that makes everything else cheaper.
Scaling Problems: When Growth Breaks the System
Process gaps and communication failures are damaging at any project size. But as projects grow – more team members, more features, more stakeholders, faster release cadence – complexity increases not just in the product but in the organization around it. Processes that worked well for a team of five often break down at twenty. This is not a failure of the original process design. It is a predictable consequence of scaling without intentional adjustment. The table below shows the most common scaling challenges and the specific risks each one introduces.
| Scaling Challenge | What Changes | Risk Introduced |
| Team size doubles | More communication channels, more handoff points | Misalignment grows faster than headcount |
| Feature complexity grows | More cross-team dependencies, more integration surface | Delays compound; one team blocks several others |
| Release cadence increases | Less time between validation and deployment | Quality issues reach production more frequently |
| Stakeholder count rises | More review gates, more conflicting priorities | Decision paralysis; velocity drops despite more people |
| Legacy systems involved | Undocumented behavior, brittle integrations, knowledge gaps | Surprises emerge late when cost of change is highest |
Scaling requires deliberate changes to process, governance, and communication structures – not just more people doing the same things. Without those changes, growth introduces instability rather than progress. The teams that scale successfully are the ones that treat organizational design as a continuous engineering problem, not a one-time setup.
The Cost of Finding Problems Too Late
One of the most consistent findings in software engineering research is that the cost of fixing a problem grows dramatically the later it is discovered. A requirements misunderstanding caught in the design phase takes hours to resolve. The same misunderstanding caught in QA takes days. Discovered post-launch, it can take weeks – and cost relationships as well as money. This principle is widely cited, and yet the structural conditions that drive late discovery persist on project after project.
The root cause is almost always the same: insufficient feedback loops. Feedback loops are the mechanisms that surface information about the current state of the project – what is working, what is not, what assumptions are proving wrong – quickly enough to act on. Short feedback loops catch problems early. Long or absent feedback loops let problems compound undetected until they become crises. A “we’ll handle it later” mindset rarely works in complex software projects. By the time problems become visible, they are already expensive to fix.
Building short feedback loops into a project is not complicated, but it requires deliberate design. It means running demos with real stakeholders at the end of every sprint, not just at major milestones. It means integrating and testing code continuously rather than in a final integration sprint. It means involving QA from the first sprint rather than treating it as a handoff at the end. None of these practices are new or exotic. What prevents their adoption is usually organizational pressure – the perception that moving fast means skipping review. In practice, the opposite is true. Teams that invest in short feedback loops move faster over the life of a project because they spend far less time on rework.
Late discovery also carries a morale cost that is easy to overlook. When developers spend significant time building something that turns out to be wrong – because requirements were ambiguous, because integration assumptions were not validated – the psychological effect is real. Good engineers want to build things that work and matter. Repeatedly delivering work that gets thrown away or radically reworked erodes engagement and drives the kind of attrition that project leaders often attribute to compensation, when the real cause was a structural failure that made the work feel pointless.
How to Build a System Where Good Teams Actually Succeed
The common thread across every failure mode discussed in this post is that they are structural – and therefore fixable. The organizations that deliver software reliably are not the ones with the most exceptional individuals. They are the ones that have invested in the conditions that allow ordinary good engineers to do extraordinary work. The table below outlines the six structural areas that most directly determine delivery outcomes, and what needs to change in each.
| Area | What Needs to Change | Outcome |
| Process | Structured discovery, sprint ceremonies, definition of done | Predictability – teams know what done means and plan to it |
| Governance | Clear ownership, decision rights, escalation paths | Faster decisions, fewer revisits, accountable delivery |
| Communication | Fixed stakeholder cadence, honest status reporting, cross-functional standups | Alignment maintained without crisis communications |
| Estimation | Historical data, risk buffers, iterative re-forecasting | Realistic timelines that stakeholders can trust |
| Technical leadership | ADRs, architecture reviews, consistent standards | Coherent systems that scale and resist regression |
| Risk management | Risk log, weekly review, proactive mitigation | Problems surface early when options are still open |
None of these changes require a large PMO or heavy process overhead. They require deliberate design decisions, consistent enforcement, and a leadership culture that treats organizational structure as seriously as technical architecture. Successful projects are built on systems that support teams – not just on the talent of the individuals within them.
How Developex Approaches Structural Delivery Risk
At Developex, we approach software development as a structured system rather than a sequence of isolated tasks. Our process begins with a strong discovery phase, where we align business goals, validate technical feasibility, and identify potential risks – ensuring that development starts with clarity and shared understanding. We emphasize governance and ownership, so that decisions are made efficiently and responsibilities are clearly defined. Sprint ceremonies, quality gates, and retrospectives are treated as non-negotiable, not the first things dropped under deadline pressure.
Communication is perhaps the area where our clients report the biggest difference from previous development experiences. We structure stakeholder updates on a fixed cadence, present project health honestly rather than optimistically, and surface risks and blockers as soon as they are identified – rather than waiting until they become crises. When things go wrong, and in complex software projects something always does, our teams escalate quickly, communicate clearly, and bring solutions alongside the problem. This builds the kind of trust that allows difficult conversations to happen early and constructively, rather than late and defensively.
The result, across a wide range of project types and industries, is consistent: clients who have worked with us on structurally challenging engagements – large team sizes, complex integrations, tight timelines, legacy system dependencies – regularly describe the experience as different from others they have run. Not because the challenges were smaller, but because the structure around the team gave everyone the visibility, clarity, and support they needed to handle those challenges effectively. That is the outcome we build toward on every engagement: not just a delivered product, but a delivery experience that demonstrates what is possible when structure and talent work together.
Conclusion
Software project failure is rarely the result of weak teams. More often, it is the result of systems that fail to support those teams effectively. Processes, governance, communication, and leadership are not secondary concerns – they are fundamental to successful delivery. Without them, even the most experienced teams will struggle to achieve consistent results.
The patterns described in this post are predictable and preventable. Process gaps that let problems accumulate, governance failures that leave decisions unmade or contested, communication breakdowns that let misalignments compound, scaling traps that break what used to work – all of these have known solutions. What makes them persistent is not their complexity but their invisibility. They live in the assumptions nobody challenged, the decisions nobody documented, the risks nobody tracked, and the conversations nobody had.
At Developex, we have seen that the most successful projects are built on clarity, alignment, and structure. By addressing these foundational elements – before the first sprint, not after the first crisis – organizations can turn complex challenges into manageable, predictable outcomes.
Ready to build a structure that actually works? Let’s talk





